structure changed commit.
This commit is contained in:
@@ -1,19 +0,0 @@
|
||||
---
|
||||
# dir:
|
||||
# text: Java全栈面试
|
||||
# icon: laptop-code
|
||||
# collapsible: true
|
||||
# expanded: true
|
||||
# link: true
|
||||
# index: true
|
||||
title: 数据结构
|
||||
index: true
|
||||
# icon: laptop-code
|
||||
# sidebar: true
|
||||
# toc: true
|
||||
# editLink: false
|
||||
---
|
||||
## 7 数据结构和算法
|
||||
|
||||
> 数据结构和算法
|
||||
|
||||
283
src/interview/DataStructure/DataStructure.md
Normal file
283
src/interview/DataStructure/DataStructure.md
Normal file
@@ -0,0 +1,283 @@
|
||||
---
|
||||
# dir:
|
||||
# text: Java全栈面试
|
||||
# icon: laptop-code
|
||||
# collapsible: true
|
||||
# expanded: true
|
||||
# link: true
|
||||
# index: true
|
||||
title: 数据结构
|
||||
index: true
|
||||
# icon: laptop-code
|
||||
# sidebar: true
|
||||
# toc: true
|
||||
# editLink: false
|
||||
---
|
||||
## 7 数据结构和算法
|
||||
|
||||
> 数据结构和算法
|
||||
|
||||
### 7.1 数据结构基础
|
||||
|
||||
#### 如何理解基础的数据结构?
|
||||
|
||||
避免孤立的学习知识点,要关联学习。比如实际应用当中,我们经常使用的是**查找,排序以及增删改**,这在我们的各种管理系统、数据库系统、操作系统等当中,十分常用,我们通过这个线索将知识点串联起来:
|
||||
|
||||
- **数组**的下标寻址十分迅速,但计算机的内存是有限的,故数组的长度也是有限的,实际应用当中的数据往往十分庞大;而且无序数组的查找最坏情况需要遍历整个数组;后来人们提出了二分查找,二分查找要求数组的构造一定有序,二分法查找解决了普通数组查找复杂度过高的问题。任何一种数组无法解决的问题就是插入、删除操作比较复杂,因此,在一个增删查改比较频繁的数据结构中,数组不会被优先考虑
|
||||
- **普通链表**由于它的结构特点被证明根本不适合进行查找
|
||||
- **哈希表**是数组和链表的折中,同时它的设计依赖散列函数的设计,数组不能无限长、链表也不适合查找,所以也不适合大规模的查找
|
||||
- **二叉查找树**因为可能退化成链表,同样不适合进行查找
|
||||
- **AVL树**是为了解决二叉查找树可能退化成链表问题。**AVL树是严格的平衡二叉树**,平衡条件必须满足(所有节点的左右子树高度差的绝对值不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况。
|
||||
- **红黑树**是二叉查找树和AVL树的折中。它是一种弱平衡二叉树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,**红黑树是一种弱平衡二叉树**(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
|
||||
- **多路查找树** 是大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。
|
||||
- **B树**与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。它的应用是文件系统及部分非关系型数据库索引。
|
||||
- **B+树**在B树基础上,为叶子结点增加链表指针(B树+叶子有序链表),所有关键字都在叶子结点 中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中。通常用于关系型数据库(如Mysql)和操作系统的文件系统中。
|
||||
- **B\*树**是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针, 在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3。
|
||||
- **R树**是用来做空间数据存储的树状数据结构。例如给地理位置,矩形和多边形这类多维数据建立索引。
|
||||
- **Trie树**是自然语言处理中最常用的数据结构,很多字符串处理任务都会用到。Trie树本身是一种有限状态自动机,还有很多变体。什么模式匹配、正则表达式,都与这有关。
|
||||
|
||||
### 7.2 算法思想
|
||||
|
||||
#### 有哪些常见的算法思想?
|
||||
|
||||
- **分治算法** :分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解
|
||||
- **动态规划算法**: 通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。和分治算法最大的差别:适用于动态规划算法求解的问题经过分解后得到的子问题往往不是相互独立的,而是下一个子阶段的求解是建立在上一个子阶段的解的基础上的。
|
||||
- **贪心算法**: 保证每次操作都是局部最优的,并且最后得到的结果是全局最优的
|
||||
- **二分法**: 比如重要的二分法,比如二分查找;二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
|
||||
- **搜索算法**: 主要包含BFS,DFS
|
||||
- **Backtracking(回溯)**: 属于 DFS, 回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法
|
||||
|
||||
### 7.3 常见排序算法
|
||||
|
||||
#### 有哪些常见的排序算法?
|
||||
|
||||
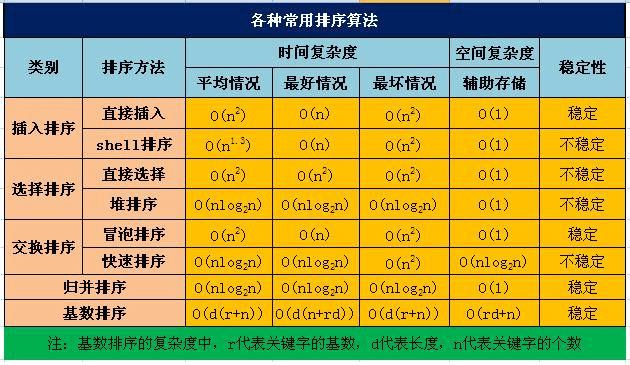
在综合复杂度及稳定性情况下,通常**希尔, 快排和 归并**需要重点掌握
|
||||
|
||||
|
||||
|
||||
- 冒泡排序
|
||||
|
||||
(Bubble Sort)
|
||||
|
||||
- 它是一种较简单的排序算法。它会遍历若干次要排序的数列,每次遍历时,它都会从前往后依次的比较相邻两个数的大小;如果前者比后者大,则交换它们的位置。这样,一次遍历之后,最大的元素就在数列的末尾! 采用相同的方法再次遍历时,第二大的元素就被排列在最大元素之前。重复此操作,直到整个数列都有序为止
|
||||
|
||||
- 快速排序
|
||||
|
||||
(Quick Sort)
|
||||
|
||||
- 它的基本思想是: 选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
|
||||
|
||||
- 插入排序
|
||||
|
||||
(Insertion Sort)
|
||||
|
||||
- 直接插入排序(Straight Insertion Sort)的基本思想是: 把n个待排序的元素看成为一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
|
||||
|
||||
- Shell排序
|
||||
|
||||
(Shell Sort)
|
||||
|
||||
- 希尔排序实质上是一种分组插入方法。它的基本思想是: 对于n个待排序的数列,取一个小于n的整数gap(gap被称为步长)将待排序元素分成若干个组子序列,所有距离为gap的倍数的记录放在同一个组中;然后,对各组内的元素进行直接插入排序。 这一趟排序完成之后,每一个组的元素都是有序的。然后减小gap的值,并重复执行上述的分组和排序。重复这样的操作,当gap=1时,整个数列就是有序的。
|
||||
|
||||
- 选择排序
|
||||
|
||||
(Selection sort)
|
||||
|
||||
- 它的基本思想是: 首先在未排序的数列中找到最小(or最大)元素,然后将其存放到数列的起始位置;接着,再从剩余未排序的元素中继续寻找最小(or最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
|
||||
|
||||
- 堆排序
|
||||
|
||||
(Heap Sort)
|
||||
|
||||
- 堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
|
||||
|
||||
- 归并排序
|
||||
|
||||
(Merge Sort)
|
||||
|
||||
- 将两个的有序数列合并成一个有序数列,我们称之为"归并"。归并排序(Merge Sort)就是利用归并思想对数列进行排序。
|
||||
|
||||
- 桶排序
|
||||
|
||||
(Bucket Sort)
|
||||
|
||||
- 桶排序(Bucket Sort)的原理很简单,将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
|
||||
|
||||
- 基数排序
|
||||
|
||||
(Radix Sort)
|
||||
|
||||
- 它的基本思想是: 将整数按位数切割成不同的数字,然后按每个位数分别比较。具体做法是: 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列
|
||||
|
||||
### 7.4 大数据处理算法
|
||||
|
||||
#### 何谓海量数据处理? 解决的思路?
|
||||
|
||||
所谓海量数据处理,无非就是基于海量数据上的存储、处理、操作。何谓海量,就是数据量太大,所以导致要么是无法在较短时间内迅速解决,要么是数据太大,导致无法一次性装入内存。
|
||||
|
||||
那解决办法呢?
|
||||
|
||||
- **针对时间**: 我们可以采用巧妙的算法搭配合适的数据结构,如Bloom filter/Hash/bit-map/堆/数据库或倒排索引/trie树;
|
||||
- **针对空间**: 无非就一个办法: 大而化小,分而治之(hash映射);
|
||||
- **集群|分布式**: 通俗点来讲,单机就是处理装载数据的机器有限(只要考虑cpu,内存,硬盘的数据交互); 而集群适合分布式处理,并行计算(更多考虑节点和节点间的数据交互)。
|
||||
|
||||
#### 大数据处理之分治思想?
|
||||
|
||||
分而治之/hash映射 + hash统计 + 堆/快速/归并排序,说白了,就是先映射,而后统计,最后排序:
|
||||
|
||||
- **分而治之/hash映射**: 针对数据太大,内存受限,只能是: 把大文件化成(取模映射)小文件,即16字方针: 大而化小,各个击破,缩小规模,逐个解决
|
||||
- **hash_map统计**: 当大文件转化了小文件,那么我们便可以采用常规的hash_map(ip,value)来进行频率统计。
|
||||
- **堆/快速排序**: 统计完了之后,便进行排序(可采取堆排序),得到次数最多的IP。
|
||||
|
||||
#### 海量日志数据,提取出某日访问百度次数最多的那个IP?
|
||||
|
||||
分析: “首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如%1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map对那1000个文件中的所有IP进行频率统计,然后依次找出各个文件中频率最大的那个IP)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。”
|
||||
|
||||
关于本题,还有几个问题,如下:
|
||||
|
||||
- Hash取模是一种等价映射,不会存在同一个元素分散到不同小文件中的情况,即这里采用的是mod1000算法,那么相同的IP在hash取模后,只可能落在同一个文件中,不可能被分散的。因为如果两个IP相等,那么经过Hash(IP)之后的哈希值是相同的,将此哈希值取模(如模1000),必定仍然相等。
|
||||
- 那到底什么是hash映射呢? 简单来说,就是为了便于计算机在有限的内存中处理big数据,从而通过一种映射散列的方式让数据均匀分布在对应的内存位置(如大数据通过取余的方式映射成小树存放在内存中,或大文件映射成多个小文件),而这个映射散列方式便是我们通常所说的hash函数,设计的好的hash函数能让数据均匀分布而减少冲突。尽管数据映射到了另外一些不同的位置,但数据还是原来的数据,只是代替和表示这些原始数据的形式发生了变化而已。
|
||||
|
||||
#### 寻找热门查询,300万个查询字符串中统计最热门的10个查询?
|
||||
|
||||
原题: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
|
||||
|
||||
解答: 由上面第1题,我们知道,数据大则划为小的,如如一亿个Ip求Top 10,可先%1000将ip分到1000个小文件中去,并保证一种ip只出现在一个文件中,再对每个小文件中的ip进行hashmap计数统计并按数量排序,最后归并或者最小堆依次处理每个小文件的top10以得到最后的结。
|
||||
|
||||
但如果数据规模比较小,能一次性装入内存呢?比如这第2题,虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去(300万个字符串假设没有重复,都是最大长度,那么最多占用内存3M*1K/4=0.75G。所以可以将所有字符串都存放在内存中进行处理),而现在只是需要一个合适的数据结构,在这里,HashTable绝对是我们优先的选择。
|
||||
|
||||
所以我们放弃分而治之/hash映射的步骤,直接上hash统计,然后排序。So,针对此类典型的TOP K问题,采取的对策往往是: hashmap + 堆。如下所示:
|
||||
|
||||
- **hash_map统计**: 先对这批海量数据预处理。具体方法是: 维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内用Hash表完成了统计; 堆排序: 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。所以,我们最终的时间复杂度是: O(N) + N' * O(logK),(N为1000万,N’为300万)。
|
||||
|
||||
别忘了这篇文章中所述的堆排序思路: “维护k个元素的最小堆,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>...kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(x入堆,用时logk),否则不更新堆。这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk。”--第三章续、Top K算法问题的实现。
|
||||
|
||||
当然,你也可以采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
|
||||
|
||||
#### 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词?
|
||||
|
||||
- **分而治之/hash映射**: 顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
|
||||
- **hash_map统计**: 对每个小文件,采用trie树/hash_map等统计每个文件中出现的词以及相应的频率。
|
||||
- **堆/归并排序**: 取出出现频率最大的100个词(可以用含100个结点的最小堆)后,再把100个词及相应的频率存入文件,这样又得到了5000个文件。最后就是把这5000个文件进行归并(类似于归并排序)的过程了。
|
||||
|
||||
#### 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10?
|
||||
|
||||
如果每个数据元素只出现一次,而且只出现在某一台机器中,那么可以采取以下步骤统计出现次数TOP10的数据元素:
|
||||
|
||||
- **堆排序**: 在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆,比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大)。 求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据,再利用上面类似的方法求出TOP10就可以了。
|
||||
|
||||
但如果同一个元素重复出现在不同的电脑中呢,如下例子所述, 这个时候,你可以有两种方法:
|
||||
|
||||
- 遍历一遍所有数据,重新hash取摸,如此使得同一个元素只出现在单独的一台电脑中,然后采用上面所说的方法,统计每台电脑中各个元素的出现次数找出TOP10,继而组合100台电脑上的TOP10,找出最终的TOP10。
|
||||
- 或者,暴力求解: 直接统计统计每台电脑中各个元素的出现次数,然后把同一个元素在不同机器中的出现次数相加,最终从所有数据中找出TOP10。
|
||||
|
||||
#### 有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序?
|
||||
|
||||
方案1:
|
||||
|
||||
- **hash映射**: 顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为a0,a1,..a9)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
|
||||
- **hash_map统计**: 找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。注: hash_map(query,query_count)是用来统计每个query的出现次数,不是存储他们的值,出现一次,则count+1。
|
||||
- **堆/快速/归并排序**: 利用快速/堆/归并排序按照出现次数进行排序,将排序好的query和对应的query_cout输出到文件中,这样得到了10个排好序的文件(记为)。最后,对这10个文件进行归并排序(内排序与外排序相结合)。
|
||||
|
||||
方案2: 一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
|
||||
|
||||
方案3: 与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
|
||||
|
||||
#### 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
|
||||
|
||||
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
|
||||
|
||||
- **分而治之/hash映射**: 遍历文件a,对每个url求取,然后根据所取得的值将url分别存储到1000个小文件(记为,这里漏写个了a1)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为)。这样处理后,所有可能相同的url都在对应的小文件()中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
|
||||
- **hash_set统计**: 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
|
||||
|
||||
如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。”
|
||||
|
||||
#### 怎么在海量数据中找出重复次数最多的一个?
|
||||
|
||||
方案: 先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
|
||||
|
||||
#### 上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据?
|
||||
|
||||
方案: 上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后利用堆取出前N个出现次数最多的数据。
|
||||
|
||||
#### 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析?
|
||||
|
||||
方案1: 如果文件比较大,无法一次性读入内存,可以采用hash取模的方法,将大文件分解为多个小文件,对于单个小文件利用hash_map统计出每个小文件中10个最常出现的词,然后再进行归并处理,找出最终的10个最常出现的词。
|
||||
|
||||
方案2: 通过hash取模将大文件分解为多个小文件后,除了可以用hash_map统计出每个小文件中10个最常出现的词,也可以用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度),最终同样找出出现最频繁的前10个词(可用堆来实现),时间复杂度是O(n*lg10)。
|
||||
|
||||
#### 一个文本文件,找出前10个经常出现的词,但这次文件比较长,说是上亿行或十亿行,总之无法一次读入内存,问最优解?
|
||||
|
||||
方案1: 首先根据用hash并求模,将文件分解为多个小文件,对于单个文件利用上题的方法求出每个文件件中10个最常出现的词。然后再进行归并处理,找出最终的10个最常出现的词。
|
||||
|
||||
#### 100w个数中找出最大的100个数?
|
||||
|
||||
方案1: 采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
|
||||
|
||||
方案2: 采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
|
||||
|
||||
方案3: 在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
|
||||
|
||||
#### 5亿个int找它们的中位数?
|
||||
|
||||
- **思路一**
|
||||
|
||||
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
|
||||
|
||||
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。即可以先将int64分成224个区域,然后确定区域的第几大数,在将该区域分成220个子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
|
||||
|
||||
- **思路二**
|
||||
|
||||
同样需要做两遍统计,如果数据存在硬盘上,就需要读取2次。
|
||||
|
||||
方法同基数排序有些像,开一个大小为65536的Int数组,第一遍读取,统计Int32的高16位的情况,也就是0-65535,都算作0,65536 - 131071都算作1。就相当于用该数除以65536。Int32 除以 65536的结果不会超过65536种情况,因此开一个长度为65536的数组计数就可以。每读取一个数,数组中对应的计数+1,考虑有负数的情况,需要将结果加32768后,记录在相应的数组内。
|
||||
|
||||
第一遍统计之后,遍历数组,逐个累加统计,看中位数处于哪个区间,比如处于区间k,那么0- k-1的区间里数字的数量sum应该`<n/2`(2.5亿)。而k+1 - 65535的计数和也`<n/2`,第二遍统计同上面的方法类似,但这次只统计处于区间k的情况,也就是说(x / 65536) + 32768 = k。统计只统计低16位的情况。并且利用刚才统计的sum,比如sum = 2.49亿,那么现在就是要在低16位里面找100万个数(2.5亿-2.49亿)。这次计数之后,再统计一下,看中位数所处的区间,最后将高位和低位组合一下就是结果了。
|
||||
|
||||
#### 在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
|
||||
|
||||
- 方案1: 采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
|
||||
- 方案2: 也可采用分治,划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
|
||||
|
||||
#### 给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
|
||||
|
||||
用位图/Bitmap的方法,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
|
||||
|
||||
### 7.5 加密算法
|
||||
|
||||
#### 什么是摘要算法?有哪些?
|
||||
|
||||
消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据无法被解密,目前可以解密逆向的只有CRC32算法,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。消息摘要算法不存在密钥的管理与分发问题,适合于分布式网络上使用。消息摘要算法主要应用在“数字签名”领域,作为对明文的摘要算法。
|
||||
|
||||
- **何谓数字签名?**
|
||||
|
||||
数字签名主要用到了非对称密钥加密技术与数字摘要技术。数字签名技术是将摘要信息用发送者的私钥加密,与原文一起传送给接收者。接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与解密的摘要信息对比。如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过.
|
||||
|
||||
因此数字签名能够验证信息的完整性。
|
||||
|
||||
数字签名是个加密的过程,数字签名验证是个解密的过程。
|
||||
|
||||
- **有哪些摘要算法**?
|
||||
|
||||
著名的摘要算法有RSA公司的MD5算法和SHA-1算法及其大量的变体
|
||||
|
||||
#### 什么是加密算法?有哪些?
|
||||
|
||||
数据加密的基本过程就是对原来为明文的文件或数据按某种算法进行处理,使其成为不可读的一段代码为“密文”,使其只能在输入相应的密钥之后才能显示出原容,通过这样的途径来达到保护数据不被非法人窃取、阅读的目的。 该过程的逆过程为解密,即将该编码信息转化为其原来数据的过程。
|
||||
|
||||
**加密算法分类**
|
||||
|
||||
密钥加密技术的密码体制分为**对称密钥**体制和**非对称密**钥体制两种。相应地,对数据加密的技术分为两类,即对称加密(私人密钥加密)和非对称加密(公开密钥加密)。
|
||||
|
||||
对称加密以数据加密标准(**DES**,Data Encryption Standard)算法为典型代表,非对称加密通常以**RSA**(Rivest Shamir Adleman)算法为代表。
|
||||
|
||||
对称加密的加密密钥和解密密钥相同。非对称加密的加密密钥和解密密钥不同,加密密钥可以公开而解密密钥需要保密
|
||||
|
||||
#### 什么是国密算法?有哪些?
|
||||
|
||||
- SM1 **为对称加密**。其加密强度与AES相当。该算法不公开,调用该算法时,需要通过**加密芯片的接口进行调用**。
|
||||
- SM2 **非对称加密**,基于ECC。该算法已公开。由于该算法基于ECC,故其签名速度与秘钥生成速度都快于RSA。ECC 256位(SM2采用的就是ECC 256位的一种)安全强度比RSA 2048位高,但运算速度快于RSA。
|
||||
- SM3 **消息摘要**。可以用MD5作为对比理解。该算法已公开。校验结果为256位。
|
||||
- SM4 无线局域网标准的**分组数据算法**。对称加密,密钥长度和分组长度均为128位。
|
||||
- SM7 是一种分组密码算法,分组长度为128比特,密钥长度为128比特。SM7适用于非接触式IC卡,应用包括身份识别类应用(门禁卡、工作证、参赛证),票务类应用(大型赛事门票、展会门票),支付与通卡类应用(积分消费卡、校园一卡通、企业一卡通等)。
|
||||
- SM9 不需要申请数字证书,适用于互联网应用的各种新兴应用的安全保障。如基于云技术的密码服务、电子邮件安全、智能终端保护、物联网安全、云存储安全等等。这些安全应用可采用手机号码或邮件地址作为公钥,实现数据加密、身份认证、通话加密、通道加密等安全应用,并具有使用方便,易于部署的特点,从而开启了普及密码算法的大门。
|
||||
460
src/interview/Database/MongoDB.md
Normal file
460
src/interview/Database/MongoDB.md
Normal file
@@ -0,0 +1,460 @@
|
||||
---
|
||||
# dir:
|
||||
# text: Java全栈面试
|
||||
# icon: laptop-code
|
||||
# collapsible: true
|
||||
# expanded: true
|
||||
# link: true
|
||||
# index: true
|
||||
title: MongoDB
|
||||
index: true
|
||||
# icon: laptop-code
|
||||
# sidebar: true
|
||||
# toc: true
|
||||
# editLink: false
|
||||
---
|
||||
|
||||
### 8.4 MongoDB
|
||||
|
||||
#### 什么是MongoDB?为什么使用MongoDB?
|
||||
|
||||
MongoDB是面向文档的NoSQL数据库,用于大量数据存储。MongoDB是一个在2000年代中期问世的数据库。属于NoSQL数据库的类别。以下是一些为什么应该开始使用MongoDB的原因
|
||||
|
||||
- **面向文档的**–由于MongoDB是NoSQL类型的数据库,它不是以关系类型的格式存储数据,而是将数据存储在文档中。这使得MongoDB非常灵活,可以适应实际的业务环境和需求。
|
||||
- **临时查询**-MongoDB支持按字段,范围查询和正则表达式搜索。可以查询返回文档中的特定字段。
|
||||
- **索引**-可以创建索引以提高MongoDB中的搜索性能。MongoDB文档中的任何字段都可以建立索引。
|
||||
- **复制**-MongoDB可以提供副本集的高可用性。副本集由两个或多个mongo数据库实例组成。每个副本集成员可以随时充当主副本或辅助副本的角色。主副本是与客户端交互并执行所有读/写操作的主服务器。辅助副本使用内置复制维护主数据的副本。当主副本发生故障时,副本集将自动切换到辅助副本,然后它将成为主服务器。
|
||||
- **负载平衡**-MongoDB使用分片的概念,通过在多个MongoDB实例之间拆分数据来水平扩展。MongoDB可以在多台服务器上运行,以平衡负载或复制数据,以便在硬件出现故障时保持系统正常运行。
|
||||
|
||||
#### MongoDB与RDBMS区别?有哪些术语?
|
||||
|
||||
下表将帮助您更容易理解Mongo中的一些概念:
|
||||
|
||||
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|
||||
| ------------ | ---------------- | ----------------------------------- |
|
||||
| database | database | 数据库 |
|
||||
| table | collection | 数据库表/集合 |
|
||||
| row | document | 数据记录行/文档 |
|
||||
| column | field | 数据字段/域 |
|
||||
| index | index | 索引 |
|
||||
| table joins | | 表连接,MongoDB不支持 |
|
||||
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
|
||||
|
||||

|
||||
|
||||
#### MongoDB聚合的管道方式?
|
||||
|
||||
Aggregation Pipline: 类似于将SQL中的group by + order by + left join ... 等操作管道化。MongoDB的聚合管道(Pipline)将MongoDB文档在一个阶段(Stage)处理完毕后将结果传递给下一个阶段(Stage)处理。**阶段(Stage)操作是可以重复的**。
|
||||
|
||||

|
||||
|
||||
#### MongoDB聚合的Map Reduce方式?
|
||||
|
||||

|
||||
|
||||
#### Spring Data 和MongoDB集成?
|
||||
|
||||

|
||||
|
||||
- 引入`mongodb-driver`, 使用最原生的方式通过Java调用mongodb提供的Java driver;
|
||||
|
||||
- 引入
|
||||
|
||||
```
|
||||
spring-data-mongo
|
||||
```
|
||||
|
||||
, 自行配置使用spring data 提供的对MongoDB的封装
|
||||
|
||||
- 使用`MongoTemplate` 的方式
|
||||
- 使用`MongoRespository` 的方式
|
||||
|
||||
- 引入`spring-data-mongo-starter`, 采用spring autoconfig机制自动装配,然后再使用`MongoTemplate`或者`MongoRespository`方式。
|
||||
|
||||
#### MongoDB 有哪几种存储引擎?
|
||||
|
||||
MongoDB一共提供了三种存储引擎:WiredTiger,MMAPV1和In Memory;在MongoDB3.2之前采用的是MMAPV1; 后续版本v3.2开始默认采用WiredTiger; 且在v4.2版本中移除了MMAPV1的引擎。
|
||||
|
||||
#### 谈谈你对MongoDB WT存储引擎的理解?
|
||||
|
||||
从几个方面回答,比如:
|
||||
|
||||
- **插件式存储引擎架构**
|
||||
|
||||
实现了Server层和存储引擎层的解耦,可以支持多种存储引擎,如MySQL既可以支持B-Tree结构的InnoDB存储引擎,还可以支持LSM结构的RocksDB存储引擎。
|
||||
|
||||
- **B-Tree + Page**
|
||||
|
||||

|
||||
|
||||
上图是WiredTiger在内存里面的大概布局图,通过它我们可梳理清楚存储引擎是如何将数据加载到内存,然后如何通过相应数据结构来支持查询、插入、修改操作的。
|
||||
|
||||
内存里面B-Tree包含三种类型的page,即rootpage、internal page和leaf page,前两者包含指向其子页的page index指针,不包含集合中的真正数据,leaf page包含集合中的真正数据即keys/values和指向父页的home指针;
|
||||
|
||||
- **为什么是Page**?
|
||||
|
||||
数据以page为单位加载到cache、cache里面又会生成各种不同类型的page及为不同类型的page分配不同大小的内存、eviction触发机制和reconcile动作都发生在page上、page大小持续增加时会被分割成多个小page,所有这些操作都是围绕一个page来完成的。
|
||||
|
||||
Page的典型生命周期如下图所示:
|
||||
|
||||

|
||||
|
||||
- **什么是CheckPoint**?
|
||||
|
||||
本质上来说,Checkpoint相当于一个日志,记录了上次Checkpoint后相关数据文件的变化。作用: 一是将内存里面发生修改的数据写到数据文件进行持久化保存,确保数据一致性; 二是实现数据库在某个时刻意外发生故障,再次启动时,缩短数据库的恢复时间,WiredTiger存储引擎中的Checkpoint模块就是来实现这个功能的。
|
||||
|
||||
一个Checkpoint包含关键信息如下图所示:
|
||||
|
||||

|
||||
|
||||
每个checkpoint包含一个root page、三个指向磁盘具体位置上pages的列表以及磁盘上文件的大小。
|
||||
|
||||
- **如何理解WT事务机制**?
|
||||
|
||||
要了解实现先要知道它的事务的构造和使用相关的技术,WT在实现事务的时使用主要是使用了三个技术:**snapshot(事务快照)**、**MVCC (多版本并发控制)\**和\**redo log(重做日志)**,为了实现这三个技术,它还定义了一个基于这三个技术的事务对象和**全局事务管理器**。
|
||||
|
||||
- **如何理解WT缓存淘汰**?
|
||||
|
||||
eviction cache是一个LRU cache,即页面置换算法缓冲区,它对数据页采用的是**分段局部扫描和淘汰**,而不是对内存中所有的数据页做全局管理。基本思路是一个线程阶段性的去扫描各个btree,并把btree可以进行淘汰的数据页添加到一个lru queue中,当queue填满了后记录下这个过程当前的btree对象和btree的位置(这个位置是为了作为下次阶段性扫描位置),然后对queue中的数据页按照访问热度排序,最后各个淘汰线程按照淘汰优先级淘汰queue中的数据页,整个过程是周期性重复。WT的这个evict过程涉及到多个eviction thread和hazard pointer技术。
|
||||
|
||||
**WT的evict过程都是以page为单位做淘汰,而不是以K/V。这一点和memcache、redis等常用的缓存LRU不太一样,因为在磁盘上数据的最小描述单位是page block,而不是记录**。
|
||||
|
||||
#### MongoDB为什么要引入复制集?有哪些成员?
|
||||
|
||||
- **什么是复制集**?
|
||||
|
||||
保证数据在生产部署时的**冗余和可靠性**,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险。换一句话来说,还能提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且,由不同的服务器为不同的用户提供服务,提高整个系统的负载。
|
||||
|
||||
在**MongoDB中就是复制集(replica set)**: 一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面。实例中包含一个主导,接受客户端所有的写入操作,其他都是副本实例,从主服务器上获得数据并保持同步。
|
||||
|
||||

|
||||
|
||||
- 基本的成员
|
||||
|
||||
?
|
||||
|
||||
- 主节点(Primary)
|
||||
|
||||
|
||||
|
||||
包含了所有的写操作的日志。但是副本服务器集群包含有所有的主服务器数据,因此当主服务器挂掉了,就会在副本服务器上重新选取一个成为主服务器。MongoDB还细化将从节点(Primary)进行了细化
|
||||
|
||||
- **Priority0** Priority0节点的选举优先级为0,不会被选举为Primary
|
||||
|
||||
- Hidden
|
||||
|
||||
|
||||
|
||||
隐藏节点将不会收到来自应用程序的请求, 可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务
|
||||
|
||||
- **Delayed** Delayed节点必须是Hidden节点,并且其数据落后与Primary一段时间(可配置,比如1个小时);当错误或者无效的数据写入Primary时,可通过Delayed节点的数据来恢复到之前的时间点。
|
||||
|
||||
- **从节点(Seconary)** 正常情况下,复制集的Seconary会参与Primary选举(自身也可能会被选为Primary),并从Primary同步最新写入的数据,以保证与Primary存储相同的数据;增加Secondary节点可以提供复制集的读服务能力,同时提升复制集的可用性。
|
||||
|
||||
- **仲裁节点(Arbiter)** Arbiter节点只参与投票,不能被选为Primary,并且不从Primary同步数据。比如你部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary。
|
||||
|
||||
#### MongoDB复制集常见部署架构?
|
||||
|
||||
分别从三节点的单数据中心,和五节点的多数据中心来说:
|
||||
|
||||
三节点的单数据中心
|
||||
|
||||
- 三节点:一主两从方式
|
||||
- 一个主节点;
|
||||
- 两个从节点组成,主节点宕机时,这两个从节点都可以被选为主节点。
|
||||
|
||||

|
||||
|
||||
当主节点宕机后,两个从节点都会进行竞选,其中一个变为主节点,当原主节点恢复后,作为从节点加入当前的复制集群即可。
|
||||
|
||||

|
||||
|
||||
- 一主一从一仲裁方式
|
||||
- 一个主节点
|
||||
- 一个从节点,可以在选举中成为主节点
|
||||
- 一个仲裁节点,在选举中,只进行投票,不能成为主节点
|
||||
|
||||

|
||||
|
||||
当主节点宕机时,将会选择从节点成为主,主节点修复后,将其加入到现有的复制集群中即可。
|
||||
|
||||

|
||||
|
||||
对于具有5个成员的复制集,成员的一些可能的分布包括(相关注意事项和三个节点一致,这里仅展示分布方案):
|
||||
|
||||
- 两个数据中心
|
||||
|
||||
:数据中心1的三个成员和数据中心2的两个成员。
|
||||
|
||||
- 如果数据中心1发生故障,则复制集将变为只读。
|
||||
- 如果数据中心2发生故障,则复制集将保持可写状态,因为数据中心1中的成员可以创建多数。
|
||||
|
||||
- 三个数据中心
|
||||
|
||||
:两个成员是数据中心1,两个成员是数据中心2,一个成员是站点数据中心3。
|
||||
|
||||
- 如果任何数据中心发生故障,复制集将保持可写状态,因为其余成员可以举行选举。
|
||||
|
||||
例如,以下5个成员复制集将其成员分布在三个数据中心中。
|
||||
|
||||

|
||||
|
||||
#### MongoDB复制集是如何保证数据高可用的?
|
||||
|
||||
通过两方面阐述:一个是选举机制,另一个是故障转移期间的回滚。
|
||||
|
||||
- **如何选出Primary主节点的?**
|
||||
|
||||
假设复制集内**能够投票的成员**数量为N,则大多数为 N/2 + 1,当复制集内存活成员数量不足大多数时,整个复制集将**无法选举出Primary,复制集将无法提供写服务,处于只读状态**。
|
||||
|
||||
举例:3投票节点需要2个节点的赞成票,容忍选举失败次数为1;5投票节点需要3个节点的赞成票,容忍选举失败次数为2;通常投票节点为奇数,这样可以减少选举失败的概率。
|
||||
|
||||
在以下的情况将触发选举机制:
|
||||
|
||||
1. 往复制集中新加入节点
|
||||
2. 初始化复制集时
|
||||
3. 对复制集进行维护时,比如`rs.stepDown()`或者`rs.reconfig()`操作时
|
||||
4. 从节点失联时,比如超时(默认是10秒)
|
||||
|
||||
- **故障转移期间的回滚**
|
||||
|
||||
当成员在故障转移后重新加入其复制集时,回滚将还原以前的主在数据库上的写操作。 **本质上就是保证数据的一致性**。
|
||||
|
||||
仅当主服务器接受了在主服务器降级之前辅助服务器未成功复制的写操作时,才需要回滚。 当主数据库作为辅助数据库重新加入集合时,它会还原或“回滚”其写入操作,以保持数据库与其他成员的一致性。
|
||||
|
||||
#### MongoDB复制集如何同步数据?
|
||||
|
||||
复制集中的数据同步是为了维护共享数据集的最新副本,包括复制集的辅助成员同步或复制其他成员的数据。 MongoDB使用两种形式的数据同步:
|
||||
|
||||
- 初始同步(Initial Sync)
|
||||
|
||||
|
||||
|
||||
以使用完整的数据集填充新成员, 即
|
||||
|
||||
全量同步
|
||||
|
||||
- 新节点加入,无任何oplog,此时需先进性initial sync
|
||||
- initial sync开始时,会主动将_initialSyncFlag字段设置为true,正常结束后再设置为false;如果节点重启时,发现_initialSyncFlag为true,说明上次全量同步中途失败了,此时应该重新进行initial sync
|
||||
- 当用户发送resync命令时,initialSyncRequested会设置为true,此时会重新开始一次initial sync
|
||||
|
||||
- 复制(Replication)
|
||||
|
||||
|
||||
|
||||
以将正在进行的更改应用于整个数据集, 即
|
||||
|
||||
增量同步
|
||||
|
||||
- initial sync结束后,接下来Secondary就会『不断拉取主上新产生的optlog并重放』
|
||||
|
||||
#### MongoDB为什么要引入分片?
|
||||
|
||||
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力, 大的查询量会将单机的CPU耗尽, 大的数据量对单机的存储压力较大, 最终会耗尽系统的内存而将压力转移到磁盘IO上。
|
||||
|
||||
为了解决这些问题, 有两个基本的方法: 垂直扩展和水平扩展。
|
||||
|
||||
- 垂直扩展:增加更多的CPU和存储资源来扩展容量。
|
||||
- 水平扩展:将数据集分布在多个服务器上。**MongoDB的分片就是水平扩展的体现**。
|
||||
|
||||
**分片设计思想**
|
||||
|
||||
分片为应对高吞吐量与大数据量提供了方法。使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,集群可以提高自己的存储容量和吞吐量。举例来说,当插入一条数据时,应用只需要访问存储这条数据的分片.
|
||||
|
||||
**分片目的**
|
||||
|
||||
- 读/写能力提升
|
||||
- 存储容量扩容
|
||||
- 高可用性
|
||||
|
||||
#### MongoDB分片集群的结构?
|
||||
|
||||
一个MongoDB的分片集群包含如下组件:
|
||||
|
||||
- `shard`: 即分片,真正的数据存储位置,以chunk为单位存数据;每个分片可以部署为一个复制集。
|
||||
- `mongos`: 查询的路由, 提供客户端和分片集群之间的接口。
|
||||
- `config servers`: 存储元数据和配置数据。
|
||||
|
||||

|
||||
|
||||
这里要注意mongos提供的是客户端application与MongoDB分片集群的路由功能,这里分片集群包含了分片的collection和非分片的collection。如下展示了通过路由访问分片的collection和非分片的collection:
|
||||
|
||||

|
||||
|
||||
#### MongoDB分片的内部是如何管理数据的呢?
|
||||
|
||||
在一个shard server内部,MongoDB还是会**把数据分为chunks**,每个chunk代表这个shard server内部一部分数据。chunk的产生,会有以下两个用途:
|
||||
|
||||
- `Splitting`:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况
|
||||
- `Balancing`:在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,chunk size默认值64M,生产库上选择适合业务的chunk size是最好的。MongoDB会自动拆分和迁移chunks。
|
||||
|
||||
分片集群的数据分布(shard节点)
|
||||
|
||||
- 使用chunk来存储数据
|
||||
- 进群搭建完成之后,默认开启一个chunk,大小是64M,
|
||||
- 存储需求超过64M,chunk会进行分裂,如果单位时间存储需求很大,设置更大的chunk
|
||||
- chunk会被自动均衡迁移。
|
||||
|
||||
**chunk分裂及迁移**
|
||||
|
||||
随着数据的增长,其中的数据大小超过了配置的chunk size,默认是64M,则这个chunk就会分裂成两个。数据的增长会让chunk分裂得越来越多。
|
||||
|
||||

|
||||
|
||||
这时候,各个shard 上的chunk数量就会不平衡。这时候,mongos中的一个组件balancer 就会执行自动平衡。把chunk从chunk数量最多的shard节点挪动到数量最少的节点。
|
||||
|
||||

|
||||
|
||||
#### MongoDB 中Collection的数据是根据什么进行分片的呢?
|
||||
|
||||
MongoDB 中Collection的数据是根据什么进行分片的呢?这就是我们要介绍的**分片键(Shard key)**;那么又是采用过了什么算法进行分片的呢?这就是紧接着要介绍的**范围分片(range sharding)\**和\**哈希分片(Hash Sharding)**。
|
||||
|
||||
- **哈希分片(Hash Sharding)**
|
||||
|
||||
分片过程中利用哈希索引作为分片,基于哈希片键最大的好处就是保证数据在各个节点分布基本均匀。
|
||||
|
||||
对于基于哈希的分片,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块。在使用基于哈希分片的系统中,拥有**相近分片键**的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。
|
||||
|
||||

|
||||
|
||||
- **范围分片(range sharding)**
|
||||
|
||||
将单个Collection的数据分散存储在多个shard上,用户可以指定根据集合内文档的某个字段即shard key来进行范围分片(range sharding)。
|
||||
|
||||
对于基于范围的分片,MongoDB按照片键的范围把数据分成不同部分:
|
||||
|
||||

|
||||
|
||||
在使用片键做范围划分的系统中,拥有**相近分片键**的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
|
||||
|
||||
- **哈希和范围的结合**
|
||||
|
||||
如下是基于X索引字段进行范围分片,但是随着X的增长,大于20的数据全部进入了Chunk C, 这导致了数据的不均衡。 
|
||||
|
||||
这时对X索引字段建哈希索引:
|
||||
|
||||

|
||||
|
||||
#### MongoDB如何做备份恢复?
|
||||
|
||||
- JSON格式:mongoexport/mongoimport
|
||||
|
||||
JSON可读性强但体积较大,JSON虽然具有较好的跨版本通用性,但其只保留了数据部分,不保留索引,账户等其他基础信息。
|
||||
|
||||
- BSON格式:mongoexport/mongoimport
|
||||
|
||||
BSON则是二进制文件,体积小但对人类几乎没有可读性。
|
||||
|
||||
#### MongoDB如何设计文档模型?
|
||||
|
||||
举几个例子:
|
||||
|
||||
- **多态模式**
|
||||
|
||||
当集合中的所有文档都具有**相似但不相同的结构**时,我们将其称为多态模式; 比如运动员的运动记录:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- **属性模式**
|
||||
|
||||
出于性能原因考虑,为了优化搜索我们可能需要许多索引以照顾到所有子集。创建所有这些索引可能会降低性能。属性模式为这种情况提供了一个很好的解决方案。
|
||||
|
||||
假设现在有一个关于电影的集合。其中所有文档中可能都有类似的字段:标题、导演、制片人、演员等等。假如我们希望在上映日期这个字段进行搜索,这时面临的挑战是“哪个上映日期”?在不同的国家,电影通常在不同的日期上映。
|
||||
|
||||
```json
|
||||
{
|
||||
title: "Star Wars",
|
||||
director: "George Lucas",
|
||||
...
|
||||
release_US: ISODate("1977-05-20T01:00:00+01:00"),
|
||||
release_France: ISODate("1977-10-19T01:00:00+01:00"),
|
||||
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
|
||||
release_UK: ISODate("1977-12-27T01:00:00+01:00"),
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
使用属性模式,我们可以将此信息移至数组中并减少对索引需求。我们将这些信息转换成一个包含键值对的数组:
|
||||
|
||||
```json
|
||||
{
|
||||
title: "Star Wars",
|
||||
director: "George Lucas",
|
||||
…
|
||||
releases: [
|
||||
{
|
||||
location: "USA",
|
||||
date: ISODate("1977-05-20T01:00:00+01:00")
|
||||
},
|
||||
{
|
||||
location: "France",
|
||||
date: ISODate("1977-10-19T01:00:00+01:00")
|
||||
},
|
||||
{
|
||||
location: "Italy",
|
||||
date: ISODate("1977-10-20T01:00:00+01:00")
|
||||
},
|
||||
{
|
||||
location: "UK",
|
||||
date: ISODate("1977-12-27T01:00:00+01:00")
|
||||
},
|
||||
…
|
||||
],
|
||||
…
|
||||
}
|
||||
```
|
||||
|
||||
- **桶模式**
|
||||
|
||||
这种模式在处理物联网(IOT)、实时分析或通用时间序列数据时特别有效。通过将数据放在一起,我们可以更容易地将数据组织成特定的组,提高发现历史趋势或提供未来预测的能力,同时还能对存储进行优化。
|
||||
|
||||
随着数据在一段时间内持续流入(时间序列数据),我们可能倾向于将每个测量值存储在自己的文档中。然而,这种倾向是一种非常偏向于关系型数据处理的方式。如果我们有一个传感器每分钟测量温度并将其保存到数据库中,我们的数据流可能看起来像这样:
|
||||
|
||||
```json
|
||||
{
|
||||
sensor_id: 12345,
|
||||
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
|
||||
temperature: 40
|
||||
}
|
||||
|
||||
{
|
||||
sensor_id: 12345,
|
||||
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
|
||||
temperature: 40
|
||||
}
|
||||
|
||||
{
|
||||
sensor_id: 12345,
|
||||
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
|
||||
temperature: 41
|
||||
}
|
||||
```
|
||||
|
||||
通过将桶模式应用于数据模型,我们可以在节省索引大小、简化潜在的查询以及在文档中使用预聚合数据的能力等方面获得一些收益。获取上面的数据流并对其应用桶模式,我们可以得到:
|
||||
|
||||
```json
|
||||
{
|
||||
sensor_id: 12345,
|
||||
start_date: ISODate("2019-01-31T10:00:00.000Z"),
|
||||
end_date: ISODate("2019-01-31T10:59:59.000Z"),
|
||||
measurements: [
|
||||
{
|
||||
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
|
||||
temperature: 40
|
||||
},
|
||||
{
|
||||
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
|
||||
temperature: 40
|
||||
},
|
||||
…
|
||||
{
|
||||
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
|
||||
temperature: 42
|
||||
}
|
||||
],
|
||||
transaction_count: 42,
|
||||
sum_temperature: 2413
|
||||
}
|
||||
```
|
||||
530
src/interview/Database/Mysql.md
Normal file
530
src/interview/Database/Mysql.md
Normal file
@@ -0,0 +1,530 @@
|
||||
---
|
||||
# dir:
|
||||
# text: Java全栈面试
|
||||
# icon: laptop-code
|
||||
# collapsible: true
|
||||
# expanded: true
|
||||
# link: true
|
||||
# index: true
|
||||
title: Mysql
|
||||
index: true
|
||||
# icon: laptop-code
|
||||
# sidebar: true
|
||||
# toc: true
|
||||
# editLink: false
|
||||
---
|
||||
|
||||
## 8 数据库
|
||||
|
||||
> 数据库相关,包括MySQL,Redis,MongoDB, ElasticSearch等。
|
||||
|
||||
### 8.1 原理和SQL
|
||||
|
||||
#### 什么是事务?事务基本特性ACID?
|
||||
|
||||
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
|
||||
|
||||

|
||||
|
||||
- 事务基本特性ACID?:
|
||||
- **A原子性(atomicity)** 指的是一个事务中的操作要么全部成功,要么全部失败。
|
||||
- **C一致性(consistency)** 指的是数据库总是从一个一致性的状态转换到另外一个一致性的状态。比如A转账给B100块钱,假设中间sql执行过程中系统崩溃A也不会损失100块,因为事务没有提交,修改也就不会保存到数据库。
|
||||
- **I隔离性(isolation)** 指的是一个事务的修改在最终提交前,对其他事务是不可见的。
|
||||
- **D持久性(durability)** 指的是一旦事务提交,所做的修改就会永久保存到数据库中。
|
||||
|
||||
#### 数据库中并发一致性问题?
|
||||
|
||||
在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题。
|
||||
|
||||
- **丢失修改**
|
||||
|
||||
T1 和 T2 两个事务都对一个数据进行修改,T1 先修改,T2 随后修改,T2 的修改覆盖了 T1 的修改。
|
||||
|
||||

|
||||
|
||||
- **读脏数据**
|
||||
|
||||
T1 修改一个数据,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2 读取的数据是脏数据。
|
||||
|
||||

|
||||
|
||||
- **不可重复读**
|
||||
|
||||
T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
|
||||
|
||||

|
||||
|
||||
- **幻影读**
|
||||
|
||||
T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
|
||||
|
||||

|
||||
|
||||
#### 事务的隔离等级?
|
||||
|
||||
- **未提交读(READ UNCOMMITTED)** 事务中的修改,即使没有提交,对其它事务也是可见的。
|
||||
- **提交读(READ COMMITTED)** 一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
|
||||
- **可重复读(REPEATABLE READ)** 保证在同一个事务中多次读取同样数据的结果是一样的。
|
||||
- **可串行化(SERIALIZABLE)** 强制事务串行执行。
|
||||
|
||||
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|
||||
| :------: | :--: | :--------: | :----: |
|
||||
| 未提交读 | √ | √ | √ |
|
||||
| 提交读 | × | √ | √ |
|
||||
| 可重复读 | × | × | √ |
|
||||
| 可串行化 | × | × | × |
|
||||
|
||||
#### ACID靠什么保证的呢?
|
||||
|
||||
- **A原子性(atomicity)** 由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql
|
||||
- **C一致性(consistency)** 一般由代码层面来保证
|
||||
- **I隔离性(isolation)** 由MVCC来保证
|
||||
- **D持久性(durability)** 由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复
|
||||
|
||||
#### SQL 优化的实践经验?
|
||||
|
||||
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
|
||||
|
||||
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
|
||||
|
||||
```sql
|
||||
select id from t where num is null
|
||||
```
|
||||
|
||||
最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.
|
||||
|
||||
备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。
|
||||
|
||||
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
|
||||
|
||||
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
|
||||
|
||||
```sql
|
||||
select id from t where num = 0
|
||||
```
|
||||
|
||||
3.应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
|
||||
|
||||
4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
|
||||
|
||||
```sql
|
||||
select id from t where num=10 or Name = 'admin'
|
||||
```
|
||||
|
||||
可以这样查询:
|
||||
|
||||
```sql
|
||||
select id from t where num = 10
|
||||
union all
|
||||
select id from t where Name = 'admin'
|
||||
```
|
||||
|
||||
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
|
||||
|
||||
```sql
|
||||
select id from t where num in(1,2,3)
|
||||
```
|
||||
|
||||
对于连续的数值,能用 between 就不要用 in 了:
|
||||
|
||||
```sql
|
||||
select id from t where num between 1 and 3
|
||||
```
|
||||
|
||||
很多时候用 exists 代替 in 是一个好的选择:
|
||||
|
||||
```sql
|
||||
select num from a where num in(select num from b)
|
||||
```
|
||||
|
||||
用下面的语句替换:
|
||||
|
||||
```sql
|
||||
select num from a where exists(select 1 from b where num=a.num)
|
||||
```
|
||||
|
||||
6.下面的查询也将导致全表扫描:
|
||||
|
||||
```sql
|
||||
select id from t where name like ‘%abc%’
|
||||
```
|
||||
|
||||
若要提高效率,可以考虑全文检索。
|
||||
|
||||
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
|
||||
|
||||
```sql
|
||||
select id from t where num = @num
|
||||
```
|
||||
|
||||
可以改为强制查询使用索引:
|
||||
|
||||
```sql
|
||||
select id from t with(index(索引名)) where num = @num
|
||||
```
|
||||
|
||||
.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
|
||||
|
||||
```sql
|
||||
select id from t where num/2 = 100
|
||||
```
|
||||
|
||||
应改为:
|
||||
|
||||
```sql
|
||||
select id from t where num = 100*2
|
||||
```
|
||||
|
||||
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
|
||||
|
||||
```sql
|
||||
select id from t where substring(name,1,3) = ’abc’ -–name以abc开头的id
|
||||
select id from t where datediff(day,createdate,’2005-11-30′) = 0 -–‘2005-11-30’ --生成的id
|
||||
```
|
||||
|
||||
应改为:
|
||||
|
||||
```sql
|
||||
select id from t where name like 'abc%'
|
||||
select id from t where createdate >= '2005-11-30' and createdate < '2005-12-1'
|
||||
```
|
||||
|
||||
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
|
||||
|
||||
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
|
||||
|
||||
12.不要写一些没有意义的查询,如需要生成一个空表结构:
|
||||
|
||||
```sql
|
||||
select col1,col2 into #t from t where 1=0
|
||||
```
|
||||
|
||||
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
|
||||
|
||||
```sql
|
||||
create table #t(…)
|
||||
```
|
||||
|
||||
13.Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
|
||||
|
||||
14.对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
|
||||
|
||||
15.select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是一定要杜绝的。
|
||||
|
||||
16.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
|
||||
|
||||
17.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
|
||||
|
||||
18.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连 接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
|
||||
|
||||
19.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
|
||||
|
||||
20.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
|
||||
|
||||
21.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
|
||||
|
||||
1. 避免频繁创建和删除临时表,以减少系统表资源的消耗。临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件, 最好使用导出表。
|
||||
|
||||
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
|
||||
|
||||
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
|
||||
|
||||
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
|
||||
|
||||
26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
|
||||
|
||||
27.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
|
||||
|
||||
28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
|
||||
|
||||
29.尽量避免大事务操作,提高系统并发能力。
|
||||
|
||||
30.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
|
||||
|
||||
#### Buffer Pool、Redo Log Buffer 和undo log、redo log、bin log 概念以及关系?
|
||||
|
||||
- Buffer Pool 是 MySQL 的一个非常重要的组件,因为针对数据库的增删改操作都是在 Buffer Pool 中完成的
|
||||
- Undo log 记录的是数据操作前的样子
|
||||
- redo log 记录的是数据被操作后的样子(redo log 是 Innodb 存储引擎特有)
|
||||
- bin log 记录的是整个操作记录(这个对于主从复制具有非常重要的意义)
|
||||
|
||||
#### 从准备更新一条数据到事务的提交的流程描述?
|
||||
|
||||

|
||||
|
||||
- 首先执行器根据 MySQL 的执行计划来查询数据,先是从缓存池中查询数据,如果没有就会去数据库中查询,如果查询到了就将其放到缓存池中
|
||||
- 在数据被缓存到缓存池的同时,会写入 undo log 日志文件
|
||||
- 更新的动作是在 BufferPool 中完成的,同时会将更新后的数据添加到 redo log buffer 中
|
||||
- 完成以后就可以提交事务,在提交的同时会做以下三件事
|
||||
- 将redo log buffer中的数据刷入到 redo log 文件中
|
||||
- 将本次操作记录写入到 bin log文件中
|
||||
- 将 bin log 文件名字和更新内容在 bin log 中的位置记录到redo log中,同时在 redo log 最后添加 commit 标记
|
||||
|
||||
### 8.2 MySQL
|
||||
|
||||
#### 能说下myisam 和 innodb的区别吗?
|
||||
|
||||
**myisam**引擎是5.1版本之前的默认引擎,支持全文检索、压缩、空间函数等,但是不支持**事务**和**行级锁**,所以一般用于有大量查询少量插入的场景来使用,而且myisam不支持**外键**,并且索引和数据是分开存储的。
|
||||
|
||||
**innodb**是基于B+Tree索引建立的,和myisam相反它支持事务、外键,并且通过MVCC来支持高并发,索引和数据存储在一起。
|
||||
|
||||
#### 说下MySQL的索引有哪些吧?
|
||||
|
||||
索引在什么层面?
|
||||
|
||||
首先,索引是在**存储引擎层实现**的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
|
||||
|
||||
有哪些?
|
||||
|
||||
- **B+Tree 索引**
|
||||
- 是大多数 MySQL 存储引擎的默认索引类型。
|
||||
- **哈希索引**
|
||||
- 哈希索引能以 O(1) 时间进行查找,但是失去了有序性;
|
||||
- InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
|
||||
- **全文索引**
|
||||
- MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
|
||||
- 全文索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
|
||||
- InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
|
||||
- **空间数据索引**
|
||||
- MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
|
||||
|
||||
#### 什么是B+树?为什么B+树成为主要的SQL数据库的索引实现?
|
||||
|
||||
- **什么是B+Tree?**
|
||||
|
||||
B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
|
||||
|
||||

|
||||
|
||||
- **为什么是B+Tree**?
|
||||
- 为了减少磁盘读取次数,决定了树的高度不能高,所以必须是先B-Tree;
|
||||
- 以页为单位读取使得一次 I/O 就能完全载入一个节点,且相邻的节点也能够被预先载入;所以数据放在叶子节点,本质上是一个Page页;
|
||||
- 为了支持范围查询以及关联关系, 页中数据需要有序,且页的尾部节点指向下个页的头部;
|
||||
- **B+树索引可分为聚簇索引和非聚簇索引**?
|
||||
|
||||
1. 主索引就是聚簇索引(也称聚集索引,clustered index)
|
||||
2. 辅助索引(有时也称非聚簇索引或二级索引,secondary index,non-clustered index)。
|
||||
|
||||

|
||||
|
||||
如上图,**主键索引的叶子节点保存的是真正的数据。而辅助索引叶子节点的数据区保存的是主键索引关键字的值**。
|
||||
|
||||
假如要查询name = C 的数据,其搜索过程如下:a) 先在辅助索引中通过C查询最后找到主键id = 9; b) 在主键索引中搜索id为9的数据,最终在主键索引的叶子节点中获取到真正的数据。所以通过辅助索引进行检索,需要检索两次索引。
|
||||
|
||||
之所以这样设计,一个原因就是:如果和MyISAM一样在主键索引和辅助索引的叶子节点中都存放数据行指针,一旦数据发生迁移,则需要去重新组织维护所有的索引。
|
||||
|
||||
#### 那你知道什么是覆盖索引和回表吗?
|
||||
|
||||
覆盖索引指的是在一次查询中,如果一个索引包含或者说覆盖所有需要查询的字段的值,我们就称之为覆盖索引,而不再需要回表查询。
|
||||
|
||||
而要确定一个查询是否是覆盖索引,我们只需要explain sql语句看Extra的结果是否是“Using index”即可。
|
||||
|
||||
比如:
|
||||
|
||||
```sql
|
||||
explain select * from user where age=1; // 查询的name无法从索引数据获取
|
||||
explain select id,age from user where age=1; //可以直接从索引获取
|
||||
```
|
||||
|
||||
#### 什么是MVCC? 说说MySQL实现MVCC的原理?
|
||||
|
||||
- **什么是MVCC?**
|
||||
|
||||
MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
|
||||
|
||||
在Mysql的InnoDB引擎中就是指在已提交读(READ COMMITTD)和可重复读(REPEATABLE READ)这两种隔离级别下的事务对于SELECT操作会访问版本链中的记录的过程。
|
||||
|
||||
这就使得别的事务可以修改这条记录,反正每次修改都会在版本链中记录。SELECT可以去版本链中拿记录,这就实现了读-写,写-读的并发执行,提升了系统的性能。
|
||||
|
||||
- **MySQL的InnoDB引擎实现MVCC的3个基础点**
|
||||
|
||||
1. **隐式字段**
|
||||
|
||||

|
||||
|
||||
如上图,DB_ROW_ID是数据库默认为该行记录生成的唯一隐式主键;DB_TRX_ID是当前操作该记录的事务ID; 而DB_ROLL_PTR是一个回滚指针,用于配合undo日志,指向上一个旧版本;delete flag没有展示出来。
|
||||
|
||||
1. **undo log**
|
||||
|
||||

|
||||
|
||||
从上面,我们就可以看出,不同事务或者相同事务的对同一记录的修改,会导致该记录的undo log成为一条记录版本线性表,既链表,undo log的链首就是最新的旧记录,链尾就是最早的旧记录
|
||||
|
||||
1. **ReadView**
|
||||
|
||||
已提交读和可重复读的区别就在于它们生成ReadView的策略不同。
|
||||
|
||||
ReadView中主要就是有个列表来存储我们系统中当前活跃着的读写事务,也就是begin了还未提交的事务。通过这个列表来判断记录的某个版本是否对当前事务可见。假设当前列表里的事务id为[80,100]。
|
||||
|
||||
a) 如果你要访问的记录版本的事务id为50,比当前列表最小的id80小,那说明这个事务在之前就提交了,所以对当前活动的事务来说是可访问的。
|
||||
|
||||
b) 如果你要访问的记录版本的事务id为90,发现此事务在列表id最大值和最小值之间,那就再判断一下是否在列表内,如果在那就说明此事务还未提交,所以版本不能被访问。如果不在那说明事务已经提交,所以版本可以被访问。
|
||||
|
||||
c) 如果你要访问的记录版本的事务id为110,那比事务列表最大id100都大,那说明这个版本是在ReadView生成之后才发生的,所以不能被访问。
|
||||
|
||||
这些记录都是去undo log 链里面找的,先找最近记录,如果最近这一条记录事务id不符合条件,不可见的话,再去找上一个版本再比较当前事务的id和这个版本事务id看能不能访问,以此类推直到返回可见的版本或者结束。
|
||||
|
||||
- **举个例子** ,在已提交读隔离级别下:
|
||||
|
||||
比如此时有一个事务id为100的事务,修改了name,使得的name等于小明2,但是事务还没提交。则此时的版本链是
|
||||
|
||||

|
||||
|
||||
那此时另一个事务发起了select 语句要查询id为1的记录,那此时生成的ReadView 列表只有[100]。那就去版本链去找了,首先肯定找最近的一条,发现trx_id是100,也就是name为小明2的那条记录,发现在列表内,所以不能访问。
|
||||
|
||||
这时候就通过指针继续找下一条,name为小明1的记录,发现trx_id是60,小于列表中的最小id,所以可以访问,直接访问结果为小明1。
|
||||
|
||||
那这时候我们把事务id为100的事务提交了,并且新建了一个事务id为110也修改id为1的记录,并且不提交事务
|
||||
|
||||

|
||||
|
||||
这时候版本链就是
|
||||
|
||||

|
||||
|
||||
这时候之前那个select事务又执行了一次查询,要查询id为1的记录。
|
||||
|
||||
**已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView**。
|
||||
|
||||
1. 如果你是已提交读隔离级别,这时候你会重新一个ReadView,那你的活动事务列表中的值就变了,变成了[110]。按照上的说法,你去版本链通过trx_id对比查找到合适的结果就是小明2。
|
||||
2. 如果你是可重复读隔离级别,这时候你的ReadView还是第一次select时候生成的ReadView,也就是列表的值还是[100]。所以select的结果是小明1。所以第二次select结果和第一次一样,所以叫可重复读!
|
||||
|
||||
这就是Mysql的MVCC,通过版本链,实现多版本,可并发读-写,写-读。通过ReadView生成策略的不同实现不同的隔离级别。
|
||||
|
||||
#### MySQL 锁的类型有哪些呢?
|
||||
|
||||
**说两个维度**:
|
||||
|
||||
- 共享锁(简称S锁)和排他锁(简称X锁)
|
||||
|
||||
- **读锁**是共享的,可以通过lock in share mode实现,这时候只能读不能写。
|
||||
- **写锁**是排他的,它会阻塞其他的写锁和读锁。从颗粒度来区分,可以分为表锁和行锁两种。
|
||||
|
||||
- 表锁和行锁
|
||||
|
||||
- **表锁**会锁定整张表并且阻塞其他用户对该表的所有读写操作,比如alter修改表结构的时候会锁表。
|
||||
|
||||
- 行锁
|
||||
|
||||
又可以分为乐观锁和悲观锁
|
||||
|
||||
- 悲观锁可以通过for update实现
|
||||
- 乐观锁则通过版本号实现。
|
||||
|
||||
**两个维度结合来看**:
|
||||
|
||||
- 共享锁(行锁):Shared Locks
|
||||
- 读锁(s锁),多个事务对于同一数据可以共享访问,不能操作修改
|
||||
- 使用方法:
|
||||
- 加锁:SELECT * FROM table WHERE id=1 LOCK IN SHARE MODE
|
||||
- 释锁:COMMIT/ROLLBACK
|
||||
- 排他锁(行锁):Exclusive Locks
|
||||
- 写锁(X锁),互斥锁/独占锁,事务获取了一个数据的X锁,其他事务就不能再获取该行的读锁和写锁(S锁、X锁),只有获取了该排他锁的事务是可以对数据行进行读取和修改
|
||||
- 使用方法:
|
||||
- DELETE/ UPDATE/ INSERT -- 加锁
|
||||
- SELECT * FROM table WHERE ... FOR UPDATE -- 加锁
|
||||
- COMMIT/ROLLBACK -- 释锁
|
||||
- 意向共享锁(IS)
|
||||
- 一个数据行加共享锁前必须先取得该表的IS锁,意向共享锁之间是可以相互兼容的 意向排它锁(IX) 一个数据行加排他锁前必须先取得该表的IX锁,意向排它锁之间是可以相互兼容的 意向锁(IS、IX)是InnoDB引擎操作数据之前自动加的,不需要用户干预; 意义: 当事务操作需要锁表时,只需判断意向锁是否存在,存在时则可快速返回该表不能启用表锁
|
||||
- 意向共享锁(IS锁)(表锁):Intention Shared Locks
|
||||
- 表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁 前必须先取得该表的IS锁。
|
||||
- 意向排它锁(IX锁)(表锁):Intention Exclusive Locks
|
||||
- 表示事务准备给数据行加入排他锁,说明事务在一个数据行加排他 锁前必须先取得该表的IX锁。
|
||||
|
||||
#### 你们数据量级多大?分库分表怎么做的?
|
||||
|
||||
首先分库分表分为垂直和水平两个方式,一般来说我们拆分的顺序是先垂直后水平。
|
||||
|
||||
- **垂直分库**
|
||||
|
||||
基于现在微服务拆分来说,都是已经做到了垂直分库了
|
||||
|
||||
- **垂直分表**
|
||||
|
||||
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
|
||||
|
||||
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
|
||||
|
||||

|
||||
|
||||
- **水平分表**
|
||||
|
||||
首先根据业务场景来决定使用什么字段作为分表字段(sharding_key),比如我们现在日订单1000万,我们大部分的场景来源于C端,我们可以用user_id作为sharding_key,数据查询支持到最近3个月的订单,超过3个月的做归档处理,那么3个月的数据量就是9亿,可以分1024张表,那么每张表的数据大概就在100万左右。
|
||||
|
||||
比如用户id为100,那我们都经过hash(100),然后对1024取模,就可以落到对应的表上了。
|
||||
|
||||

|
||||
|
||||
#### 那分表后的ID怎么保证唯一性的呢?
|
||||
|
||||
因为我们主键默认都是自增的,那么分表之后的主键在不同表就肯定会有冲突了。有几个办法考虑:
|
||||
|
||||
- 设定步长,比如1-1024张表我们分别设定1-1024的基础步长,这样主键落到不同的表就不会冲突了。
|
||||
- 分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种
|
||||
- 分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。
|
||||
|
||||
#### 分表后非sharding_key的查询怎么处理呢?
|
||||
|
||||
- 可以做一个mapping表,比如这时候商家要查询订单列表怎么办呢?不带user_id查询的话你总不能扫全表吧?所以我们可以做一个映射关系表,保存商家和用户的关系,查询的时候先通过商家查询到用户列表,再通过user_id去查询。
|
||||
- 大宽表,一般而言,商户端对数据实时性要求并不是很高,比如查询订单列表,可以把订单表同步到离线(实时)数仓,再基于数仓去做成一张宽表,再基于其他如es提供查询服务。
|
||||
- 数据量不是很大的话,比如后台的一些查询之类的,也可以通过多线程扫表,然后再聚合结果的方式来做。或者异步的形式也是可以的。
|
||||
|
||||
```java
|
||||
List<Callable<List<User>>> taskList = Lists.newArrayList();
|
||||
for (int shardingIndex = 0; shardingIndex < 1024; shardingIndex++) {
|
||||
taskList.add(() -> (userMapper.getProcessingAccountList(shardingIndex)));
|
||||
}
|
||||
List<ThirdAccountInfo> list = null;
|
||||
try {
|
||||
list = taskExecutor.executeTask(taskList);
|
||||
} catch (Exception e) {
|
||||
//do something
|
||||
}
|
||||
|
||||
public class TaskExecutor {
|
||||
public <T> List<T> executeTask(Collection<? extends Callable<T>> tasks) throws Exception {
|
||||
List<T> result = Lists.newArrayList();
|
||||
List<Future<T>> futures = ExecutorUtil.invokeAll(tasks);
|
||||
for (Future<T> future : futures) {
|
||||
result.add(future.get());
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### MySQL主从复制?
|
||||
|
||||
主要涉及三个线程: binlog 线程、I/O 线程和 SQL 线程。
|
||||
|
||||
- **binlog 线程** : 负责将主服务器上的数据更改写入二进制日志中。
|
||||
- **I/O 线程** : 负责从主服务器上读取二进制日志,并写入从服务器的中继日志中。
|
||||
- **SQL 线程** : 负责读取中继日志并重放其中的 SQL 语句。
|
||||
|
||||

|
||||
|
||||
**全同步复制**
|
||||
|
||||
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
|
||||
|
||||
**半同步复制**
|
||||
|
||||
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
|
||||
|
||||
#### MySQL主从的延迟怎么解决呢?
|
||||
|
||||
这个问题貌似真的是个无解的问题,只能是说自己来判断了,需要走主库的强制走主库查询。
|
||||
|
||||
#### MySQL读写分离方案?
|
||||
|
||||
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
|
||||
|
||||
读写分离能提高性能的原因在于:
|
||||
|
||||
- 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
|
||||
- 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
|
||||
- 增加冗余,提高可用性。
|
||||
|
||||
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
|
||||
|
||||

|
||||
1157
src/interview/Database/Redis.md
Normal file
1157
src/interview/Database/Redis.md
Normal file
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user