daily commited
This commit is contained in:
922
src/interview/DevelopmentFrameworkRelated/DevelopmentBasics.md
Normal file
922
src/interview/DevelopmentFrameworkRelated/DevelopmentBasics.md
Normal file
@@ -0,0 +1,922 @@
|
||||
---
|
||||
# dir:
|
||||
# text: Java全栈面试
|
||||
# icon: laptop-code
|
||||
# collapsible: true
|
||||
# expanded: true
|
||||
# link: true
|
||||
# index: true
|
||||
title: 开发基础
|
||||
index: true
|
||||
# icon: laptop-code
|
||||
# sidebar: true
|
||||
# toc: true
|
||||
# editLink: false
|
||||
---
|
||||
|
||||
## 9 开发基础
|
||||
|
||||
> 开发基础相关。
|
||||
|
||||
### 9.1 常用类库
|
||||
|
||||
#### 平时常用的开发工具库有哪些?
|
||||
|
||||
- Apache Common
|
||||
- Apache Commons是对JDK的拓展,包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动。
|
||||
- Google Guava
|
||||
- Guava工程包含了若干被Google的 Java项目广泛依赖 的核心库,例如:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string processing] 、I/O 等等。 所有这些工具每天都在被Google的工程师应用在产品服务中。
|
||||
- Hutool
|
||||
- 国产后起之秀,Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率
|
||||
- Spring常用工具类
|
||||
- Spring作为常用的开发框架,在Spring框架应用中,排在ApacheCommon,Guava, Huool等通用库后,第二优先级可以考虑使用Spring-core-xxx.jar中的util包
|
||||
|
||||
#### Java常用的JSON库有哪些?有啥注意点?
|
||||
|
||||
- FastJSON(不推荐,漏洞太多)
|
||||
- Jackson
|
||||
- Gson
|
||||
- 序列化
|
||||
- 反序列化
|
||||
- 自定义序列化和反序列化
|
||||
|
||||
#### Lombok工具库用来解决什么问题?
|
||||
|
||||
我们通常需要编写大量代码才能使类变得有用。如以下内容:
|
||||
|
||||
- `toString()`方法
|
||||
- `hashCode()` and `equals()`方法
|
||||
- `Getter` and `Setter` 方法
|
||||
- 构造函数
|
||||
|
||||
对于这种简单的类,这些方法通常是无聊的、重复的,而且是可以很容易地机械地生成的那种东西(ide通常提供这种功能)。
|
||||
|
||||
- `@Getter/@Setter`示例
|
||||
|
||||
```java
|
||||
@Setter(AccessLevel.PUBLIC)
|
||||
@Getter(AccessLevel.PROTECTED)
|
||||
private int id;
|
||||
private String shap;
|
||||
```
|
||||
|
||||
- `@ToString`示例
|
||||
|
||||
```java
|
||||
@ToString(exclude = "id", callSuper = true, includeFieldNames = true)
|
||||
public class LombokDemo {
|
||||
private int id;
|
||||
private String name;
|
||||
private int age;
|
||||
public static void main(String[] args) {
|
||||
//输出LombokDemo(super=LombokDemo@48524010, name=null, age=0)
|
||||
System.out.println(new LombokDemo());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- `@EqualsAndHashCode`示例
|
||||
|
||||
```java
|
||||
@EqualsAndHashCode(exclude = {"id", "shape"}, callSuper = false)
|
||||
public class LombokDemo {
|
||||
private int id;
|
||||
private String shap;
|
||||
}
|
||||
```
|
||||
|
||||
#### 为什么很多公司禁止使用lombok?
|
||||
|
||||
可以使用而且有着广泛的使用,但是需要理解部分注解的底层和潜在问题,否则会有坑:
|
||||
|
||||
- `@Data`: 如果只使用了`@Data`,而不使用`@EqualsAndHashCode(callSuper=true)`的话,会默认是`@EqualsAndHashCode(callSuper=false)`,这时候生成的`equals()`方法只会比较子类的属性,不会考虑从父类继承的属性,无论父类属性访问权限是否开放。
|
||||
- **代码可读性,可调试性低** 在代码中使用了Lombok,确实可以帮忙减少很多代码,因为Lombok会帮忙自动生成很多代码。但是**这些代码是要在编译阶段才会生成的**,所以在开发的过程中,其实很多代码其实是缺失的。
|
||||
- **Lombok有很强的侵入性**
|
||||
- 强J队友,如果项目组中有一个人使用了Lombok,那么其他人就必须也要安装IDE插件。
|
||||
- 如果我们需要升级到某个新版本的JDK的时候,若其中的特性在Lombok中不支持的话就会受到影响
|
||||
- **Lombok破坏了封装性**
|
||||
|
||||
举个简单的例子,我们定义一个购物车类:
|
||||
|
||||
```java
|
||||
@Data
|
||||
public class ShoppingCart {
|
||||
|
||||
//商品数目
|
||||
private int itemsCount;
|
||||
|
||||
//总价格
|
||||
private double totalPrice;
|
||||
|
||||
//商品明细
|
||||
private List items = new ArrayList<>();
|
||||
|
||||
}
|
||||
|
||||
//例子来源于《极客时间-设计模式之美》
|
||||
```
|
||||
|
||||
我们知道,购物车中商品数目、商品明细以及总价格三者之前其实是有关联关系的,如果需要修改的话是要一起修改的。
|
||||
|
||||
但是,我们使用了Lombok的`@Data`注解,对于itemsCount 和 totalPrice这两个属性。虽然我们将它们定义成 `private` 类型,但是提供了 `public` 的 `getter`、`setter` 方法。
|
||||
|
||||
外部可以通过 `setter` 方法随意地修改这两个属性的值。我们可以随意调用 `setter` 方法,来重新设置 itemsCount、totalPrice 属性的值,这也会导致其跟 items 属性的值不一致。
|
||||
|
||||
而面向对象封装的定义是:通过访问权限控制,隐藏内部数据,外部仅能通过类提供的有限的接口访问、修改内部数据。所以,暴露不应该暴露的 setter 方法,明显违反了面向对象的封装特性。
|
||||
|
||||
好的做法应该是不提供`getter/setter`,而是只提供一个public的addItem方法,同时去修改itemsCount、totalPrice以及items三个属性。(所以不能一股脑使用@Data注解)
|
||||
|
||||
- 此外,**Java14 提供的record语法糖**,来解决类似问题
|
||||
|
||||
```java
|
||||
public record Range(int min, int max) {}
|
||||
```
|
||||
|
||||
#### MapStruct工具库用来解决什么问题?
|
||||
|
||||
MapStruct是一款非常实用Java工具,主要用于解决对象之间的拷贝问题,比如PO/DTO/VO/QueryParam之间的转换问题。区别于BeanUtils这种通过反射,它通过编译器编译生成常规方法,将可以很大程度上提升效率。
|
||||
|
||||
举例:
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface UserConverter {
|
||||
UserConverter INSTANCE = Mappers.getMapper(UserConverter.class);
|
||||
|
||||
@Mapping(target = "gender", source = "sex")
|
||||
@Mapping(target = "createTime", dateFormat = "yyyy-MM-dd HH:mm:ss")
|
||||
UserVo do2vo(User var1);
|
||||
|
||||
@Mapping(target = "sex", source = "gender")
|
||||
@Mapping(target = "password", ignore = true)
|
||||
@Mapping(target = "createTime", dateFormat = "yyyy-MM-dd HH:mm:ss")
|
||||
User vo2Do(UserVo var1);
|
||||
|
||||
List<UserVo> do2voList(List<User> userList);
|
||||
|
||||
default List<UserVo.UserConfig> strConfigToListUserConfig(String config) {
|
||||
return JSON.parseArray(config, UserVo.UserConfig.class);
|
||||
}
|
||||
|
||||
default String listUserConfigToStrConfig(List<UserVo.UserConfig> list) {
|
||||
return JSON.toJSONString(list);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Lombok和MapStruct工具库的原理?
|
||||
|
||||
会发现在Lombok使用的过程中,只需要添加相应的注解,无需再为此写任何代码。自动生成的代码到底是如何产生的呢?
|
||||
|
||||
核心之处就是对于注解的解析上。JDK5引入了注解的同时,也提供了两种解析方式。
|
||||
|
||||
- **运行时解析**
|
||||
|
||||
运行时能够解析的注解,必须将@Retention设置为RUNTIME, 比如`@Retention(RetentionPolicy.RUNTIME)`,这样就可以通过反射拿到该注解。java.lang,reflect反射包中提供了一个接口AnnotatedElement,该接口定义了获取注解信息的几个方法,Class、Constructor、Field、Method、Package等都实现了该接口,对反射熟悉的朋友应该都会很熟悉这种解析方式。
|
||||
|
||||
- **编译时解析**
|
||||
|
||||
编译时解析有两种机制,分别简单描述下:
|
||||
|
||||
1)Annotation Processing Tool
|
||||
|
||||
apt自JDK5产生,JDK7已标记为过期,不推荐使用,JDK8中已彻底删除,自JDK6开始,可以使用Pluggable Annotation Processing API来替换它,apt被替换主要有2点原因:
|
||||
|
||||
- api都在com.sun.mirror非标准包下
|
||||
- 没有集成到javac中,需要额外运行
|
||||
|
||||
2)Pluggable Annotation Processing API
|
||||
|
||||
[JSR 269: Pluggable Annotation Processing API在新窗口打开](https://www.jcp.org/en/jsr/proposalDetails?id=269)自JDK6加入,作为apt的替代方案,它解决了apt的两个问题,javac在执行的时候会调用实现了该API的程序,这样我们就可以对编译器做一些增强,这时javac执行的过程如下:
|
||||
|
||||

|
||||
|
||||
Lombok本质上就是一个实现了“JSR 269 API”的程序。在使用javac的过程中,它产生作用的具体流程如下:
|
||||
|
||||
- javac对源代码进行分析,生成了一棵抽象语法树(AST)
|
||||
- 运行过程中调用实现了“JSR 269 API”的Lombok程序
|
||||
- 此时Lombok就对第一步骤得到的AST进行处理,找到@Data注解所在类对应的语法树(AST),然后修改该语法树(AST),增加getter和setter方法定义的相应树节点
|
||||
- javac使用修改后的抽象语法树(AST)生成字节码文件,即给class增加新的节点(代码块)
|
||||
|
||||

|
||||
|
||||
从上面的Lombok执行的流程图中可以看出,在Javac 解析成AST抽象语法树之后, Lombok 根据自己编写的注解处理器,动态地修改 AST,增加新的节点(即Lombok自定义注解所需要生成的代码),最终通过分析生成JVM可执行的字节码Class文件。使用Annotation Processing自定义注解是在编译阶段进行修改,而JDK的反射技术是在运行时动态修改,两者相比,反射虽然更加灵活一些但是带来的性能损耗更加大。
|
||||
|
||||
### 9.2 网络协议和工具
|
||||
|
||||
#### 什么是754层网络模型?
|
||||
|
||||
全局上理解 `7层协议,4层,5层`的对应关系。
|
||||
|
||||

|
||||
|
||||
OSI依层次结构来划分:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)
|
||||
|
||||
#### TCP建立连接过程的三次握手?
|
||||
|
||||
TCP有6种标识:SYN(建立联机) ACK(确认) PSH(传送) FIN(结束) RST(重置) URG(紧急); 然后我们来看三次握手
|
||||
|
||||
- **什么是三次握手**?
|
||||
|
||||

|
||||
|
||||
为了保证数据能到达目标,TCP采用三次握手策略:
|
||||
|
||||
1. 发送端首先发送一个带**SYN**(synchronize)标志的数据包给接收方【第一次的seq序列号是随机产生的,这样是为了网络安全,如果不是随机产生初始序列号,黑客将会以很容易的方式获取到你与其他主机之间的初始化序列号,并且伪造序列号进行攻击】
|
||||
2. 接收端收到后,回传一个带有**SYN/ACK**(acknowledgement)标志的数据包以示传达确认信息【SYN 是为了告诉发送端,发送方到接收方的通道没问题;ACK 用来验证接收方到发送方的通道没问题】
|
||||
3. 最后,发送端再回传一个带ACK标志的数据包,代表握手结束若在握手某个过程中某个阶段莫名中断,TCP协议会再次以相同的顺序发送相同的数据包
|
||||
|
||||
- **为什么要三次握手**?
|
||||
|
||||
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的
|
||||
|
||||
1. 第一次握手,发送端:什么都确认不了;接收端:对方发送正常,自己接受正常
|
||||
2. 第二次握手,发送端:对方发送,接受正常,自己发送,接受正常 ;接收端:对方发送正常,自己接受正常
|
||||
3. 第三次握手,发送端:对方发送,接受正常,自己发送,接受正常;接收端:对方发送,接受正常,自己发送,接受正常
|
||||
|
||||
- **两次握手不行吗?为什么TCP客户端最后还要发送一次确认呢**?
|
||||
|
||||
主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。经典场景:客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了。
|
||||
|
||||
1. 由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。
|
||||
2. 此时此前滞留的那一次请求连接,网络通畅了到达服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
|
||||
3. 如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
|
||||
|
||||
- **为什么三次握手,返回时,ack 值是 seq 加 1(ack = x+1)**
|
||||
|
||||
1. 假设对方接收到数据,比如sequence number = 1000,TCP Payload = 1000,数据第一个字节编号为1000,最后一个为1999,回应一个确认报文,确认号为2000,意味着编号2000前的字节接收完成,准备接收编号为2000及更多的数据
|
||||
2. 确认收到的序列,并且告诉发送端下一次发送的序列号从哪里开始(便于接收方对数据排序,便于选择重传)
|
||||
|
||||
- **TCP三次握手中,最后一次回复丢失,会发生什么**?
|
||||
|
||||
1. 如果最后一次ACK在网络中丢失,那么Server端(服务端)该TCP连接的状态仍为SYN_RECV,并且根据 TCP的超时重传机制依次等待3秒、6秒、12秒后重新发送 SYN+ACK 包,以便 Client(客户端)重新发送ACK包
|
||||
2. 如果重发指定次数后,仍然未收到ACK应答,那么一段时间后,Server(服务端)自动关闭这个连接
|
||||
3. 但是Client(客户端)认为这个连接已经建立,如果Client(客户端)端向Server(服务端)发送数据,Server端(服务端)将以RST包(Reset,标示复位,用于异常的关闭连接)响应,此时,客户端知道第三次握手失败
|
||||
|
||||
#### SYN洪泛攻击(SYN Flood,半开放攻击),怎么解决?
|
||||
|
||||
- **什么是SYN洪范泛攻击**?
|
||||
|
||||
SYN Flood利用TCP协议缺陷,发送大量伪造的TCP连接请求,常用假冒的IP或IP号段发来海量的请求连接的第一个握手包(SYN包),被攻击服务器回应第二个握手包(SYN+ACK包),因为对方是假冒IP,对方永远收不到包且不会回应第三个握手包。导致被攻击服务器保持大量SYN_RECV状态的“半连接”,并且会重试默认5次回应第二个握手包,大量随机的恶意syn占满了未完成连接队列,导致正常合法的syn排不上队列,让正常的业务请求连接不进来。【服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到SYN洪泛攻击】
|
||||
|
||||
- **如何检测 SYN 攻击?**
|
||||
|
||||
当你在服务器上看到大量的半连接状态时,特别是源IP地址是随机的,基本上可以断定这是一次SYN攻击【在 Linux/Unix 上可以使用系统自带的 netstats 命令来检测 SYN 攻击】
|
||||
|
||||
- **怎么解决**? SYN攻击不能完全被阻止,除非将TCP协议重新设计。我们所做的是尽可能的减轻SYN攻击的危害,
|
||||
|
||||
1. 缩短超时(SYN Timeout)时间
|
||||
2. 增加最大半连接数
|
||||
3. 过滤网关防护
|
||||
4. SYN cookies技术:
|
||||
1. 当服务器接受到 SYN 报文段时,不直接为该 TCP 分配资源,而只是打开一个半开的套接字。接着会使用 SYN 报文段的源 Id,目的 Id,端口号以及只有服务器自己知道的一个秘密函数生成一个 cookie,并把 cookie 作为序列号响应给客户端。
|
||||
2. 如果客户端是正常建立连接,将会返回一个确认字段为 cookie + 1 的报文段。接下来服务器会根据确认报文的源 Id,目的 Id,端口号以及秘密函数计算出一个结果,如果结果的值 + 1 等于确认字段的值,则证明是刚刚请求连接的客户端,这时候才为该 TCP 分配资源
|
||||
|
||||
#### TCP断开连接过程的四次挥手?
|
||||
|
||||
- **什么是四次挥手**?
|
||||
|
||||

|
||||
|
||||
1. 主动断开方(客户端/服务端)-发送一个 FIN,用来关闭主动断开方(客户端/服务端)到被动断开方(客户端/服务端)的数据传送
|
||||
2. 被动断开方(客户端/服务端)-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
|
||||
3. 被动断开方(客户端/服务端)-关闭与主动断开方(客户端/服务端)的连接,发送一个FIN给主动断开方(客户端/服务端)
|
||||
4. 主动断开方(客户端/服务端)-发回 ACK 报文确认,并将确认序号设置为收到序号加1
|
||||
|
||||
- **为什么连接的时候是三次握手,关闭的时候却是四次握手**?
|
||||
|
||||
1. 建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
|
||||
2. 关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以服务器可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接。因此,服务器ACK和FIN一般都会分开发送,从而导致多了一次。
|
||||
|
||||
- **为什么TCP挥手每两次中间有一个 FIN-WAIT2等待时间**?
|
||||
|
||||
主动关闭的一端调用完close以后(即发FIN给被动关闭的一端, 并且收到其对FIN的确认ACK)则进入FIN_WAIT_2状态。如果这个时候因为网络突然断掉、被动关闭的一段宕机等原因,导致主动关闭的一端不能收到被动关闭的一端发来的FIN(防止对端不发送关闭连接的FIN包给本端),这个时候就需要FIN_WAIT_2定时器, 如果在该定时器超时的时候,还是没收到被动关闭一端发来的FIN,那么直接释放这个链接,进入CLOSE状态
|
||||
|
||||
- **为什么客户端最后还要等待2MSL?为什么还有个TIME-WAIT的时间等待**?
|
||||
|
||||
1. 保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,服务器已经发送了FIN+ACK报文,请求断开,客户端却没有回应,于是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
|
||||
2. 防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失,这样新的连接中不会出现旧连接的请求报文。
|
||||
3. 2MSL,最大报文生存时间,一个MSL 30 秒,2MSL = 60s
|
||||
|
||||
- **客户端 TIME-WAIT 状态过多会产生什么后果?怎样处理**?
|
||||
|
||||
1. 作为服务器,短时间内关闭了大量的Client连接,就会造成服务器上出现大量的TIME_WAIT连接,占据大量的tuple /tApl/ ,严重消耗着服务器的资源,此时部分客户端就会显示连接不上
|
||||
2. 作为客户端,短时间内大量的短连接,会大量消耗的Client机器的端口,毕竟端口只有65535个,端口被耗尽了,后续就无法在发起新的连接了
|
||||
3. 在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上
|
||||
1. 高并发可以让服务器在短时间范围内同时占用大量端口,而端口有个0~65535的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了
|
||||
2. 短连接表示“业务处理+传输数据的时间 远远小于 TIMEWAIT超时的时间”的连接
|
||||
4. 解决方法:
|
||||
1. 用负载均衡来抗这些高并发的短请求;
|
||||
2. 服务器可以设置 SO_REUSEADDR 套接字选项来避免 TIME_WAIT状态,TIME_WAIT 状态可以通过优化服务器参数得到解决,因为发生TIME_WAIT的情况是服务器自己可控的,要么就是对方连接的异常,要么就是自己没有迅速回收资源,总之不是由于自己程序错误导致的
|
||||
3. 强制关闭,发送 RST 包越过TIMEWAIT状态,直接进入CLOSED状态
|
||||
|
||||
- **服务器出现了大量 CLOSE_WAIT 状态如何解决**?
|
||||
|
||||
大量 CLOSE_WAIT 表示程序出现了问题,对方的 socket 已经关闭连接,而我方忙于读或写没有及时关闭连接,需要检查代码,特别是释放资源的代码,或者是处理请求的线程配置。
|
||||
|
||||
- **服务端会有一个TIME_WAIT状态吗?如果是服务端主动断开连接呢**?
|
||||
|
||||
1. 发起链接的主动方基本都是客户端,但是断开连接的主动方服务器和客户端都可以充当,也就是说,只要是主动断开连接的,就会有 TIME_WAIT状态
|
||||
2. 四次挥手是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发
|
||||
3. 由于TCP连接时全双工的,因此,每个方向的数据传输通道都必须要单独进行关闭。
|
||||
|
||||
#### DNS 解析流程?
|
||||
|
||||
.com.fi国际金融域名DNS解析的步骤一共分为9步,如果每次解析都要走完9个步骤,大家浏览网站的速度也不会那么快,现在之所以能保持这么快的访问速度,其实一般的解析都是跑完第4步就可以了。除非一个地区完全是第一次访问(在都没有缓存的情况下)才会走完9个步骤,这个情况很少。
|
||||
|
||||
- 1、本地客户机提出域名解析请求,查找本地HOST文件后将该请求发送给本地的域名服务器。
|
||||
- 2、将请求发送给本地的域名服务器。
|
||||
- 3、当本地的域名服务器收到请求后,就先查询本地的缓存。
|
||||
- 4、如果有该纪录项,则本地的域名服务器就直接把查询的结果返回浏览器。
|
||||
- 5、如果本地DNS缓存中没有该纪录,则本地域名服务器就直接把请求发给根域名服务器。
|
||||
- 6、然后根域名服务器再返回给本地域名服务器一个所查询域(根的子域)的主域名服务器的地址。
|
||||
- 7、本地服务器再向上一步返回的域名服务器发送请求,然后接受请求的服务器查询自己的缓存,如果没有该纪录,则返回相关的下级的域名服务器的地址。
|
||||
- 8、重复第7步,直到找到正确的纪录。
|
||||
- 9、本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时还将结果返回给客户机。
|
||||
|
||||

|
||||
|
||||
注意事项:
|
||||
|
||||
**递归查询**:在该模式下DNS服务器接收到客户机请求,必须使用一个准确的查询结果回复客户机。如果DNS服务器本地没有存储查询DNS信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。
|
||||
|
||||
**迭代查询**:DNS所在服务器若没有可以响应的结果,会向客户机提供其他能够解析查询请求的DNS服务器地址,当客户机发送查询请求时,DNS服务器并不直接回复查询结果,而是告诉客户机另一台DNS服务器地址,客户机再向这台DNS服务器提交请求,依次循环直到返回查询的结果为止。
|
||||
|
||||
#### 为什么DNS通常基于UDP?
|
||||
|
||||
DNS通常是基于UDP的,但当数据长度大于512字节的时候,为了保证传输质量,就会使用基于TCP的实现方式
|
||||
|
||||
- **从数据包的数量以及占有网络资源的层面**
|
||||
|
||||
使用基于UDP的DNS协议只要一个请求、一个应答就好了; 而使用基于TCP的DNS协议要三次握手、发送数据以及应答、四次挥手; 明显基于TCP协议的DNS更浪费网络资源!
|
||||
|
||||
- **从数据一致性层面**
|
||||
|
||||
DNS数据包不是那种大数据包,所以使用UDP不需要考虑分包,如果丢包那么就是全部丢包,如果收到了数据,那就是收到了全部数据!所以只需要考虑丢包的情况,那就算是丢包了,重新请求一次就好了。而且DNS的报文允许填入序号字段,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答是对应的哪个请求
|
||||
|
||||
#### 什么是DNS劫持?
|
||||
|
||||
DNS劫持就是通过劫持了DNS服务器,通过某些手段取得某域名的解析记录控制权,进而修改此域名的解析结果,导致对该域名的访问由原IP地址转入到修改后的指定IP,其结果就是对特定的网址不能访问或访问的是假网址,从而实现窃取资料或者破坏原有正常服务的目的。DNS劫持通过篡改DNS服务器上的数据返回给用户一个错误的查询结果来实现的。
|
||||
|
||||
- **DNS劫持症状**
|
||||
|
||||
在某些地区的用户在成功连接宽带后,首次打开任何页面都指向ISP提供的“电信互联星空”、“网通黄页广告”等内容页面。还有就是曾经出现过用户访问Google域名的时候出现了百度的网站。这些都属于DNS劫持。
|
||||
|
||||
#### 什么是DNS污染?
|
||||
|
||||
DNS污染是一种让一般用户由于得到虚假目标主机IP而不能与其通信的方法,是一种DNS缓存投毒攻击(DNS cache poisoning)。其工作方式是:由于通常的DNS查询没有任何认证机制,而且DNS查询通常基于的UDP是无连接不可靠的协议,因此DNS的查询非常容易被篡改,通过对UDP端口53上的DNS查询进行入侵检测,一经发现与关键词相匹配的请求则立即伪装成目标域名的解析服务器(NS,Name Server)给查询者返回虚假结果。
|
||||
|
||||
而DNS污染则是发生在用户请求的第一步上,直接从协议上对用户的DNS请求进行干扰。
|
||||
|
||||
**DNS污染症状**:
|
||||
|
||||
目前一些被禁止访问的网站很多就是通过DNS污染来实现的,例如YouTube、Facebook等网站。
|
||||
|
||||
**解决方法**:
|
||||
|
||||
1. 对于DNS劫持,可以采用使用国外免费公用的DNS服务器解决。例如OpenDNS(208.67.222.222)或GoogleDNS(8.8.8.8)。
|
||||
2. 对于DNS污染,可以说,个人用户很难单单靠设置解决,通常可以使用VPN或者域名远程解析的方法解决,但这大多需要购买付费的VPN或SSH等,也可以通过修改Hosts的方法,手动设置域名正确的IP地址。
|
||||
|
||||
#### 为什么要DNS流量监控?
|
||||
|
||||
预示网络中正出现可疑或恶意代码的 DNS 组合查询或流量特征。例如:
|
||||
|
||||
- 1.来自伪造源地址的 DNS 查询、或未授权使用且无出口过滤地址的 DNS 查询,若同时观察到异常大的 DNS 查询量或使用 TCP 而非 UDP 进行 DNS 查询,这可能表明网络内存在被感染的主机,受到了 DDoS 攻击。
|
||||
- 2.异常 DNS 查询可能是针对域名服务器或解析器(根据目标 IP 地址确定)的漏洞攻击的标志。与此同时,这些查询也可能表明网络中有不正常运行的设备。原因可能是恶意软件或未能成功清除恶意软件。
|
||||
- 3.在很多情况下,DNS 查询要求解析的域名如果是已知的恶意域名,或具有域名生成算法( DGA )(与非法僵尸网络有关)常见特征的域名,或者向未授权使用的解析器发送的查询,都是证明网络中存在被感染主机的有力证据。
|
||||
- 4.DNS 响应也能显露可疑或恶意数据在网络主机间传播的迹象。例如,DNS 响应的长度或组合特征可以暴露恶意或非法行为。例如,响应消息异常巨大(放大攻击),或响应消息的 Answer Section 或 Additional Section 非常可疑(缓存污染,隐蔽通道)。
|
||||
- 5.针对自身域名组合的 DNS 响应,如果解析至不同于你发布在授权区域中的 IP 地址,或来自未授权区域主机的域名服务器的响应,或解析为名称错误( NXDOMAIN )的对区域主机名的肯定响应,均表明域名或注册账号可能被劫持或 DNS 响应被篡改。
|
||||
- 6.来自可疑 IP 地址的 DNS 响应,例如来自分配给宽带接入网络 IP 段的地址、非标准端口上出现的 DNS 流量,异常大量的解析至短生存时间( TTL )域名的响应消息,或异常大量的包含“ name error ”( NXDOMAIN )的响应消息,往往是主机被僵尸网络控制、运行恶意软件或被感染的表现。
|
||||
|
||||
#### 输入URL 到页面加载过程?
|
||||
|
||||
1. 地址栏输入URL
|
||||
2. DNS 域名解析IP
|
||||
3. 请求和响应数据
|
||||
1. 建立TCP连接(3次握手)
|
||||
2. 发送HTTP请求
|
||||
3. 服务器处理请求
|
||||
4. 返回HTTP响应结果
|
||||
5. 关闭TCP连接(4次挥手)
|
||||
4. 浏览器加载,解析和渲染
|
||||
|
||||
下图是在数据传输过程中的工作方式,在发送端是应用层-->链路层这个方向的封包过程,每经过一层都会增加该层的头部。而接收端则是从链路层-->应用层解包的过程,每经过一层则会去掉相应的首部。
|
||||
|
||||

|
||||
|
||||
#### 如何使用netstat查看服务及监听端口?
|
||||
|
||||
`netstat -t/-u/-l/-r/-n`【显示网络相关信息,-t:TCP协议,-u:UDP协议,-l:监听,-r:路由,-n:显示IP地址和端口号】
|
||||
|
||||
- 查看本机监听的端口
|
||||
|
||||
```bash
|
||||
[root@pdai-centos ~]# netstat -tlun
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
|
||||
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN
|
||||
udp 0 0 172.21.0.14:123 0.0.0.0:*
|
||||
udp 0 0 127.0.0.1:123 0.0.0.0:*
|
||||
udp6 0 0 fe80::5054:ff:fe2b::123 :::*
|
||||
udp6 0 0 ::1:123 :::*
|
||||
```
|
||||
|
||||
#### 如何使用TCPDump抓包?
|
||||
|
||||
tcpdump 是一款强大的网络抓包工具,它使用 libpcap 库来抓取网络数据包,这个库在几乎在所有的 Linux/Unix 中都有。
|
||||
|
||||
**tcpdump 的常用参数**如下:
|
||||
|
||||
```bash
|
||||
$ tcpdump -i eth0 -nn -s0 -v port 80
|
||||
```
|
||||
|
||||
- -i : 选择要捕获的接口,通常是以太网卡或无线网卡,也可以是 vlan 或其他特殊接口。如果该系统上只有一个网络接口,则无需指定。
|
||||
- -nn : 单个 n 表示不解析域名,直接显示 IP;两个 n 表示不解析域名和端口。这样不仅方便查看 IP 和端口号,而且在抓取大量数据时非常高效,因为域名解析会降低抓取速度。
|
||||
- -s0 : tcpdump 默认只会截取前 96 字节的内容,要想截取所有的报文内容,可以使用 `-s number`, number 就是你要截取的报文字节数,如果是 0 的话,表示截取报文全部内容。
|
||||
- -v : 使用 `-v`,`-vv` 和 `-vvv` 来显示更多的详细信息,通常会显示更多与特定协议相关的信息。
|
||||
- `port 80` : 这是一个常见的端口过滤器,表示仅抓取 80 端口上的流量,通常是 HTTP。
|
||||
|
||||
#### 如何使用Wireshark抓包分析?
|
||||
|
||||
Wireshark(前称Ethereal)是一个网络封包分析软件。网络封包分析软件的功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料。Wireshark使用WinPCAP作为接口,直接与网卡进行数据报文交换。
|
||||
|
||||
首先看下TCP报文首部,和wireshark捕获到的TCP包中的每个字段如下图所示:
|
||||
|
||||

|
||||
|
||||
### 9.3 开发安全
|
||||
|
||||
#### 开发中有哪些常见的Web安全漏洞?
|
||||
|
||||
通过OWASP Top 10来回答
|
||||
|
||||

|
||||
|
||||
2013版至2017版,应用程序的基础技术和结构发生了重大变化:
|
||||
|
||||
- 使用node.js和Spring Boot构建的微服务正在取代传统的单任务应用,微服务本身具有自己的安全挑战,包括微服务间互信、容器 工具、保密管理等等。原来没人期望代码要实现基于互联网的房屋,而现在这些代码就在API或RESTful服务的后面,提供给移动 应用或单页应用(SPA)的大量使用。代码构建时的假设,如受信任的调用等等,再也不存在了。
|
||||
- 使用JavaScript框架(如:Angular和React)编写的单页应用程序,允许创建高度模块化的前端用户体验;原来交付服务器端处理 的功能现在变为由客户端处理,但也带来了安全挑战。
|
||||
- JavaScript成为网页上最基本的语言。Node.js运行在服务器端,采用现代网页框架的Bootstrap、Electron、Angular和React则运 行在客户端。
|
||||
|
||||
#### 什么是注入攻击?举例说明?
|
||||
|
||||
- **什么是注入攻击?从具体的SQL注入说**?
|
||||
|
||||
重点看这条SQL,密码输入: ' OR '1'='1时,等同于不需要密码
|
||||
|
||||
```java
|
||||
String sql = "SELECT * FROM t_user WHERE username='"+userName+"' AND pwd='"+password+"'";
|
||||
```
|
||||
|
||||
- **如何解决注入攻击,比如SQL注入**?
|
||||
|
||||
1. **使用预编译处理输入参数**:要防御 SQL 注入,用户的输入就不能直接嵌套在 SQL 语句当中。使用参数化的语句,用户的输入就被限制于一个参数当中, 比如用prepareStatement
|
||||
2. **输入验证**:检查用户输入的合法性,以确保输入的内容为正常的数据。数据检查应当在客户端和服务器端都执行,之所以要执行服务器端验证,是因为客户端的校验往往只是减轻服务器的压力和提高对用户的友好度,攻击者完全有可能通过抓包修改参数或者是获得网页的源代码后,修改验证合法性的脚本(或者直接删除脚本),然后将非法内容通过修改后的表单提交给服务器等等手段绕过客户端的校验。因此,要保证验证操作确实已经执行,唯一的办法就是在服务器端也执行验证。但是这些方法很容易出现由于过滤不严导致恶意攻击者可能绕过这些过滤的现象,需要慎重使用。
|
||||
3. **错误消息处理**:防范 SQL 注入,还要避免出现一些详细的错误消息,恶意攻击者往往会利用这些报错信息来判断后台 SQL 的拼接形式,甚至是直接利用这些报错注入将数据库中的数据通过报错信息显示出来。
|
||||
4. **加密处理**:将用户登录名称、密码等数据加密保存。加密用户输入的数据,然后再将它与数据库中保存的数据比较,这相当于对用户输入的数据进行了“消毒”处理,用户输入的数据不再对数据库有任何特殊的意义,从而也就防止了攻击者注入 SQL 命令。
|
||||
|
||||
- **还有哪些注入**?
|
||||
|
||||
1. xPath注入,XPath 注入是指利用 XPath 解析器的松散输入和容错特性,能够在 URL、表单或其它信息上附带恶意的 XPath 查询代码,以获得权限信息的访问权并更改这些信息
|
||||
2. 命令注入,Java中`System.Runtime.getRuntime().exec(cmd);`可以在目标机器上执行命令,而构建参数的过程中可能会引发注入攻击
|
||||
3. LDAP注入
|
||||
4. CLRF注入
|
||||
5. email注入
|
||||
6. Host注入
|
||||
|
||||
#### 什么是CSRF?举例说明并给出开发中解决方案?
|
||||
|
||||
你这可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义发送恶意请求。
|
||||
|
||||
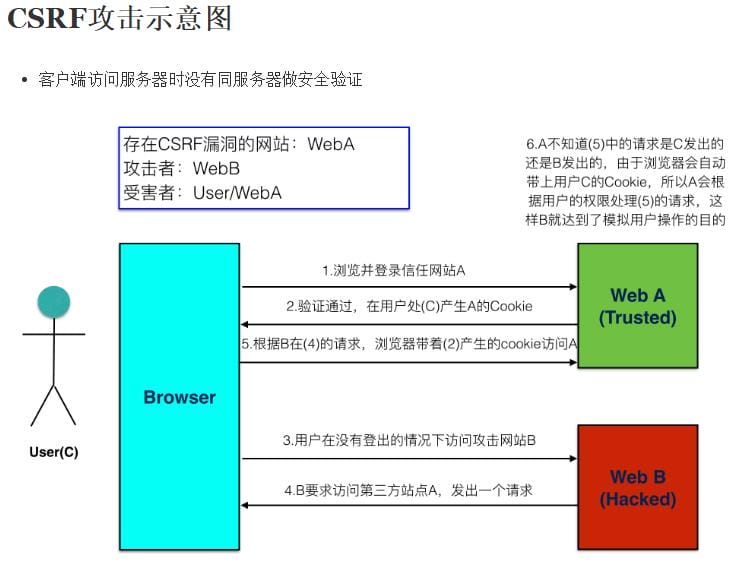
|
||||
|
||||
- **黑客能拿到Cookie吗**?
|
||||
|
||||
CSRF 攻击是黑客借助受害者的 cookie 骗取服务器的信任,但是黑客并不能拿到 cookie,也看不到 cookie 的内容。
|
||||
|
||||
对于服务器返回的结果,由于浏览器同源策略的限制,黑客也无法进行解析。因此,黑客无法从返回的结果中得到任何东西,他所能做的就是给服务器发送请求,以执行请求中所描述的命令,在服务器端直接改变数据的值,而非窃取服务器中的数据。
|
||||
|
||||
- **什么样的请求是要CSRF保护**?
|
||||
|
||||
为什么有些框架(比如Spring Security)里防护CSRF的filter限定的Method是POST/PUT/DELETE等,而没有限定GET Method?
|
||||
|
||||
我们要保护的对象是那些可以直接产生数据改变的服务,而对于读取数据的服务,则不需要进行 CSRF 的保护。通常而言GET请作为请求数据,不作为修改数据,所以这些框架没有拦截Get等方式请求。比如银行系统中转账的请求会直接改变账户的金额,会遭到 CSRF 攻击,需要保护。而查询余额是对金额的读取操作,不会改变数据,CSRF 攻击无法解析服务器返回的结果,无需保护。
|
||||
|
||||
- **为什么对请求做了CSRF拦截,但还是会报CRSF漏洞**?
|
||||
|
||||
为什么我在前端已经采用POST+CSRF Token请求,后端也对POST请求做了CSRF Filter,但是渗透测试中还有CSRF漏洞?
|
||||
|
||||
直接看下面代码。
|
||||
|
||||
```java
|
||||
// 这里没有限制POST Method,导致用户可以不通过POST请求提交数据。
|
||||
@RequestMapping("/url")
|
||||
public ReponseData saveSomething(XXParam param){
|
||||
// 数据保存操作...
|
||||
}
|
||||
```
|
||||
|
||||
PS:这一点是很容易被忽视的,在笔者经历过的几个项目的渗透测试中,多次出现。@pdai
|
||||
|
||||
- **有哪些CSRF 防御常规思路**?
|
||||
|
||||
1. **验证 HTTP Referer 字段**, 根据 HTTP 协议,在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。只需要验证referer
|
||||
2. **在请求地址中添加 token 并验证**,可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。 这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。
|
||||
3. **在 HTTP 头中自定义属性并验证**
|
||||
|
||||
- **开发中如何防御CSRF**?
|
||||
|
||||
可以通过自定义xxxCsrfFilter去拦截实现, 这里建议你参考 Spring Security - org.springframework.security.web.csrf.CsrfFilter.java。
|
||||
|
||||
#### 什么是XSS?举例说明?
|
||||
|
||||
通常XSS攻击分为:`反射型xss攻击`, `存储型xss攻击` 和 `DOM型xss攻击`。同时注意以下例子只是简单的向你解释这三种类型的攻击方式而已,实际情况比这个复杂,具体可以再结合最后一节深入理解。
|
||||
|
||||
- **反射型xss攻击?**
|
||||
|
||||
反射型的攻击需要用户主动的去访问带攻击的链接,攻击者可以通过邮件或者短信的形式,诱导受害者点开链接。如果攻击者配合短链接URL,攻击成功的概率会更高。
|
||||
|
||||
在一个反射型XSS攻击中,恶意文本属于受害者发送给网站的请求中的一部分。随后网站又把恶意文本包含进用于响应用户的返回页面中,发还给用户。
|
||||
|
||||

|
||||
|
||||
- **存储型xss攻击**?
|
||||
|
||||
这种攻击方式恶意代码会被存储在数据库中,其他用户在正常访问的情况下,也有会被攻击,影响的范围比较大。
|
||||
|
||||

|
||||
|
||||
- **DOM型xss攻击**?
|
||||
|
||||
基于DOM的XSS攻击是反射型攻击的变种。服务器返回的页面是正常的,只是我们在页面执行js的过程中,会把攻击代码植入到页面中。
|
||||
|
||||

|
||||
|
||||
- **XSS 攻击的防御**?
|
||||
|
||||
XSS攻击其实就是代码的注入。用户的输入被编译成恶意的程序代码。所以,为了防范这一类代码的注入,需要确保用户输入的安全性。对于攻击验证,我们可以采用以下两种措施:
|
||||
|
||||
1. **编码,就是转义用户的输入,把用户的输入解读为数据而不是代码**
|
||||
2. **校验,对用户的输入及请求都进行过滤检查,如对特殊字符进行过滤,设置输入域的匹配规则等**。
|
||||
|
||||
具体比如:
|
||||
|
||||
1. **对于验证输入**,我们既可以在`服务端验证`,也可以在`客户端验证`
|
||||
2. **对于持久性和反射型攻击**,`服务端验证`是必须的,服务端支持的任何语言都能够做到
|
||||
3. **对于基于DOM的XSS攻击**,验证输入在客户端必须执行,因为从服务端来说,所有发出的页面内容是正常的,只是在客户端js代码执行的过程中才发生可攻击
|
||||
4. 但是对于各种攻击方式,**我们最好做到客户端和服务端都进行处理**。
|
||||
|
||||
其它还有一些辅助措施,比如:
|
||||
|
||||
1. **入参长度限制**: 通过以上的案例我们不难发现xss攻击要能达成往往需要较长的字符串,因此对于一些可以预期的输入可以通过限制长度强制截断来进行防御。
|
||||
2. 设置cookie httponly为true(具体请看下文的解释)
|
||||
|
||||
#### 一般的渗透测试流程?
|
||||
|
||||
渗透测试就是利用我们所掌握的渗透知识,对网站进行一步一步的渗透,发现其中存在的漏洞和隐藏的风险,然后撰写一篇测试报告,提供给我们的客户。客户根据我们撰写的测试报告,对网站进行漏洞修补,以防止黑客的入侵!
|
||||
|
||||
- **渗透测试流程举例**?
|
||||
|
||||
我们现在就模拟黑客对一个网站进行渗透测试,这属于黑盒测试,我们只知道该网站的URL,其他什么的信息都不知道。
|
||||
|
||||

|
||||
|
||||
- 确定目标
|
||||
- 确定范围:测试目标的范围、ip、域名、内外网、测试账户。
|
||||
- 确定规则:能渗透到什么程度,所需要的时间、能否修改上传、能否提权、等等。
|
||||
- 确定需求:web应用的漏洞、业务逻辑漏洞、人员权限管理漏洞、等等。
|
||||
- 信息收集
|
||||
- 方式:主动扫描,开放搜索等。
|
||||
- 开放搜索:利用搜索引擎获得:后台、未授权页面、敏感url、等等。
|
||||
- 基础信息:IP、网段、域名、端口。
|
||||
- 应用信息:各端口的应用。例如web应用、邮件应用、等等。
|
||||
- 系统信息:操作系统版本
|
||||
- 版本信息:所有这些探测到的东西的版本。
|
||||
- 服务信息:中间件的各类信息,插件信息。
|
||||
- 人员信息:域名注册人员信息,web应用中发帖人的id,管理员姓名等。
|
||||
- 防护信息:试着看能否探测到防护设备。
|
||||
- 漏洞探测
|
||||
- 漏洞验证
|
||||
- 内网转发
|
||||
- 内网横向渗透
|
||||
- 权限维持
|
||||
- 痕迹清除
|
||||
- 撰写渗透测试保告
|
||||
|
||||

|
||||
|
||||
### 9.4 单元测试
|
||||
|
||||
#### 谈谈你对单元测试的理解?
|
||||
|
||||
- **什么是单元测试**?
|
||||
|
||||
单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。
|
||||
|
||||
- **为什么要写单元测试**?
|
||||
|
||||
使用单元测试可以有效地降低程序出错的机率,提供准确的文档,并帮助我们改进设计方案等等。
|
||||
|
||||
- **什么时候写单元测试**?
|
||||
|
||||
比较推荐单元测试与具体实现代码同步进行这个方案的。只有对需求有一定的理解后才能知道什么是代码的正确性,才能写出有效的单元测试来验证正确性,而能写出一些功能代码则说明对需求有一定理解了。
|
||||
|
||||
- **单元测试要写多细**?
|
||||
|
||||
单元测试不是越多越好,而是越有效越好!进一步解读就是哪些代码需要有单元测试覆盖:
|
||||
|
||||
1. 逻辑复杂的
|
||||
2. 容易出错的
|
||||
3. 不易理解的,即使是自己过段时间也会遗忘的,看不懂自己的代码,单元测试代码有助于理解代码的功能和需求
|
||||
4. 公共代码。比如自定义的所有http请求都会经过的拦截器;工具类等。
|
||||
5. 核心业务代码。一个产品里最核心最有业务价值的代码应该要有较高的单元测试覆盖率。
|
||||
|
||||
#### JUnit 5整体架构?
|
||||
|
||||
与以前版本的JUnit不同,JUnit 5由三个不同子项目中的几个不同模块组成。JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit Vintage
|
||||
|
||||
- **JUnit Platform**是基于JVM的运行测试的基础框架在,它定义了开发运行在这个测试框架上的TestEngine API。此外该平台提供了一个控制台启动器,可以从命令行启动平台,可以为Gradle和 Maven构建插件,同时提供基于JUnit 4的Runner。
|
||||
- **JUnit Jupiter**是在JUnit 5中编写测试和扩展的新编程模型和扩展模型的组合.Jupiter子项目提供了一个TestEngine在平台上运行基于Jupiter的测试。
|
||||
- **JUnit Vintage**提供了一个TestEngine在平台上运行基于JUnit 3和JUnit 4的测试。
|
||||
|
||||
架构图如下:
|
||||
|
||||

|
||||
|
||||
#### JUnit 5与Junit4的差别在哪里?
|
||||
|
||||
对比下Junit5和Junit4注解:
|
||||
|
||||
| Junit4 | Junit5 | 注释 |
|
||||
| ------------ | --------------- | ------------------------------------------------------------ |
|
||||
| @Test | @Test | 表示该方法是一个测试方法 |
|
||||
| @BeforeClass | **@BeforeAll** | 表示使用了该注解的方法应该在当前类中所有测试方法之前执行(只执行一次),并且它必须是 static方法(除非@TestInstance指定生命周期为Lifecycle.PER_CLASS) |
|
||||
| @AfterClass | **@AfterAll** | 表示使用了该注解的方法应该在当前类中所有测试方法之后执行(只执行一次),并且它必须是 static方法(除非@TestInstance指定生命周期为Lifecycle.PER_CLASS) |
|
||||
| @Before | **@BeforeEach** | 表示使用了该注解的方法应该在当前类中每一个测试方法之前执行 |
|
||||
| @After | **@AfterEach** | 表示使用了该注解的方法应该在当前类中每一个测试方法之后执行 |
|
||||
| @Ignore | @Disabled | 用于禁用(或者说忽略)一个测试类或测试方法 |
|
||||
| @Category | @Tag | 用于声明过滤测试的tag标签,该注解可以用在方法或类上 |
|
||||
|
||||
#### 你在开发中使用什么框架来做单元测试?
|
||||
|
||||
- JUnit4/5
|
||||
- Mockito, mock测试
|
||||
- Powermock, 静态util的测试
|
||||
|
||||
### 9.5 代码质量
|
||||
|
||||
#### 你们项目中是如何保证代码质量的?
|
||||
|
||||
- **checkstyle**, 静态样式检查
|
||||
- **sonarlint** Sonar是一个用于代码质量管理的开源平台,用于管理源代码的质量 通过插件形式,可以支持包括java,C#,C/C++,PL/SQL,Cobol,JavaScrip,Groovy等等二十几种编程语言的代码质量管理与检测
|
||||
- **spotbugs**, SpotBugs是Findbugs的继任者(Findbugs已经于2016年后不再维护),用于对代码进行静态分析,查找相关的漏洞; 它是一款自由软件,按照GNU Lesser General Public License 的条款发布
|
||||
|
||||
#### 你们项目中是如何做code review的?
|
||||
|
||||
Gerrit + 定期线下review
|
||||
|
||||
### 9.6 代码重构
|
||||
|
||||
#### 如何去除多余的if else?
|
||||
|
||||
- 出现if/else和switch/case的场景
|
||||
|
||||
通常业务代码会包含这样的逻辑:每种条件下会有不同的处理逻辑。比如两个数a和b之间可以通过不同的操作符(+,-,*,/)进行计算,初学者通常会这么写:
|
||||
|
||||
```java
|
||||
public int calculate(int a, int b, String operator) {
|
||||
int result = Integer.MIN_VALUE;
|
||||
|
||||
if ("add".equals(operator)) {
|
||||
result = a + b;
|
||||
} else if ("multiply".equals(operator)) {
|
||||
result = a * b;
|
||||
} else if ("divide".equals(operator)) {
|
||||
result = a / b;
|
||||
} else if ("subtract".equals(operator)) {
|
||||
result = a - b;
|
||||
}
|
||||
return result;
|
||||
}
|
||||
```
|
||||
|
||||
这种最基础的代码如何重构呢?
|
||||
|
||||
- **工厂类**
|
||||
|
||||
```java
|
||||
public class OperatorFactory {
|
||||
static Map<String, Operation> operationMap = new HashMap<>();
|
||||
static {
|
||||
operationMap.put("add", new Addition());
|
||||
operationMap.put("divide", new Division());
|
||||
// more operators
|
||||
}
|
||||
|
||||
public static Optional<Operation> getOperation(String operator) {
|
||||
return Optional.ofNullable(operationMap.get(operator));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- **枚举**
|
||||
|
||||
```java
|
||||
public enum Operator {
|
||||
ADD {
|
||||
@Override
|
||||
public int apply(int a, int b) {
|
||||
return a + b;
|
||||
}
|
||||
},
|
||||
// other operators
|
||||
|
||||
public abstract int apply(int a, int b);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
- **Command模式**
|
||||
|
||||
```java
|
||||
public class AddCommand implements Command {
|
||||
// Instance variables
|
||||
|
||||
public AddCommand(int a, int b) {
|
||||
this.a = a;
|
||||
this.b = b;
|
||||
}
|
||||
|
||||
@Override
|
||||
public Integer execute() {
|
||||
return a + b;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- **规则引擎**
|
||||
|
||||
1. 定义规则
|
||||
|
||||
```java
|
||||
public interface Rule {
|
||||
boolean evaluate(Expression expression);
|
||||
Result getResult();
|
||||
}
|
||||
```
|
||||
|
||||
1. Add 规则
|
||||
|
||||
```java
|
||||
public class AddRule implements Rule {
|
||||
@Override
|
||||
public boolean evaluate(Expression expression) {
|
||||
boolean evalResult = false;
|
||||
if (expression.getOperator() == Operator.ADD) {
|
||||
this.result = expression.getX() + expression.getY();
|
||||
evalResult = true;
|
||||
}
|
||||
return evalResult;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
1. 表达式
|
||||
|
||||
```java
|
||||
public class Expression {
|
||||
private Integer x;
|
||||
private Integer y;
|
||||
private Operator operator;
|
||||
}
|
||||
```
|
||||
|
||||
1. 规则引擎
|
||||
|
||||
```java
|
||||
public class RuleEngine {
|
||||
private static List<Rule> rules = new ArrayList<>();
|
||||
|
||||
static {
|
||||
rules.add(new AddRule());
|
||||
}
|
||||
|
||||
public Result process(Expression expression) {
|
||||
Rule rule = rules
|
||||
.stream()
|
||||
.filter(r -> r.evaluate(expression))
|
||||
.findFirst()
|
||||
.orElseThrow(() -> new IllegalArgumentException("Expression does not matches any Rule"));
|
||||
return rule.getResult();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- **策略模式**
|
||||
|
||||
1. 操作
|
||||
|
||||
```java
|
||||
public interface Opt {
|
||||
int apply(int a, int b);
|
||||
}
|
||||
|
||||
@Component(value = "addOpt")
|
||||
public class AddOpt implements Opt {
|
||||
@Autowired
|
||||
xxxAddResource resource; // 这里通过Spring框架注入了资源
|
||||
|
||||
@Override
|
||||
public int apply(int a, int b) {
|
||||
return resource.process(a, b);
|
||||
}
|
||||
}
|
||||
|
||||
@Component(value = "devideOpt")
|
||||
public class devideOpt implements Opt {
|
||||
@Autowired
|
||||
xxxDivResource resource; // 这里通过Spring框架注入了资源
|
||||
|
||||
@Override
|
||||
public int apply(int a, int b) {
|
||||
return resource.process(a, b);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
1. 策略
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class OptStrategyContext{
|
||||
|
||||
|
||||
private Map<String, Opt> strategyMap = new ConcurrentHashMap<>();
|
||||
|
||||
@Autowired
|
||||
public OptStrategyContext(Map<String, TalkService> strategyMap) {
|
||||
this.strategyMap.clear();
|
||||
this.strategyMap.putAll(strategyMap);
|
||||
}
|
||||
|
||||
public int apply(Sting opt, int a, int b) {
|
||||
return strategyMap.get(opt).apply(a, b);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 如何去除不必要的!=判空?
|
||||
|
||||
- **空对象模式**
|
||||
|
||||
```java
|
||||
public class MyParser implements Parser {
|
||||
private static Action NO_ACTION = new Action() {
|
||||
public void doSomething() { /* do nothing */ }
|
||||
};
|
||||
|
||||
public Action findAction(String userInput) {
|
||||
// ...
|
||||
if ( /* we can't find any actions */ ) {
|
||||
return NO_ACTION;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
然后便可以始终可以这么调用
|
||||
|
||||
```java
|
||||
ParserFactory.getParser().findAction(someInput).doSomething();
|
||||
```
|
||||
|
||||
- **Java8中使用Optional**
|
||||
|
||||
```java
|
||||
Outer outer = new Outer();
|
||||
if (outer != null && outer.nested != null && outer.nested.inner != null) {
|
||||
System.out.println(outer.nested.inner.foo);
|
||||
}
|
||||
```
|
||||
|
||||
我们可以通过利用 Java 8 的 Optional 类型来摆脱所有这些 null 检查。map 方法接收一个 Function 类型的 lambda 表达式,并自动将每个 function 的结果包装成一个 Optional 对象。这使我们能够在一行中进行多个 map 操作。Null 检查是在底层自动处理的。
|
||||
|
||||
```java
|
||||
Optional.of(new Outer())
|
||||
.map(Outer::getNested)
|
||||
.map(Nested::getInner)
|
||||
.map(Inner::getFoo)
|
||||
.ifPresent(System.out::println);
|
||||
```
|
||||
|
||||
还有一种实现相同作用的方式就是通过利用一个 supplier 函数来解决嵌套路径的问题:
|
||||
|
||||
```java
|
||||
Outer obj = new Outer();
|
||||
resolve(() -> obj.getNested().getInner().getFoo())
|
||||
.ifPresent(System.out::println);
|
||||
```
|
||||
|
||||
Reference in New Issue
Block a user